Problem: After an update to F39, a system continues to boot F38 kernels
The /bin/kernel-install generates entries in /boot/efi/loader/entries instead of /boot/loader/entries. Also, they are in BLS Type 1 format, and not in the legacy GRUB format. So I cannot copy them over.
I've read a bunch of docs and the man page for kernel-install(8), but they are incomprehensible. Still the key insight was that all that Systemd stuff loves to autodetect by finding this directory or that.
The way to test is: [root@chihiro zaitcev]# /bin/kernel-install -v add 6.8.5-201.fc39.x86_64 /lib/modules/6.8.5-201.fc39.x86_64/vmlinuz
Linux Plumbers Conference 2024 is pleased to host the Networking Track!
LPC Networking track is an in-person manifestation of the netdev mailing list, bringing together developers, users and vendors to discuss topics related to Linux networking. Relevant topics span from proposals for kernel changes, through user space tooling, netdev testing and CI, to presenting interesting use cases, new protocols or new, interesting problems waiting for a solution.
The goal is to allow gathering early feedback on proposals, reach consensus on long running mailing list discussions and raise awareness of interesting work and use cases.
After four years of co-locating BPF & Networking Tracks together this year we separated the two, again. Please submit to the track which feels suitable, the committee will transfer submissions between tracks as it deems necessary.
Please come and join us in the discussion. We hope to see you there!
When you have an outage caused by a performance issue, you don't want to lose precious time just to install the tools needed to diagnose it. Here is a list of "crisis tools" I recommend installing on your Linux servers by default (if they aren't already), along with the (Ubuntu) package names that they come from:
bpftrace, basic versions of opensnoop(8), execsnoop(8), runqlat(8), biosnoop(8), etc.
eBPF scripting[1]
trace-cmd
trace-cmd(1)
Ftrace CLI
nicstat
nicstat(1)
net device stats
ethtool
ethtool(8)
net device info
tiptop
tiptop(1)
PMU/PMC top
cpuid
cpuid(1)
CPU details
msr-tools
rdmsr(8), wrmsr(8)
CPU digging
(This is based on Table 4.1 "Linux Crisis Tools" in SysPerf 2.)
Some longer notes: [1] bcc and bpftrace have many overlapping tools: the bcc ones are more capable (e.g., CLI options), and the bpftrace ones can be edited on the fly. But that's not to say that one is better or faster than the other: They emit the same BPF bytecode and are equally fast once running. Also note that bcc is evolving and migrating tools from Python to libbpf C (with CO-RE and BTF) but we haven't reworked the package yet. In the future "bpfcc-tools" should get replaced with a much smaller "libbpf-tools" package that's just tool binaries.
This list is a minimum. Some servers have accelerators and you'll want their analysis tools installed as well: e.g., on Intel GPU servers, the intel-gpu-tools package; on NVIDIA, nvidia-smi. Debugging tools, like gdb(1), can also be pre-installed for immediate use in a crisis.
Essential analysis tools like these don't change that often, so this list may only need updating every few years. If you think I missed a package that is important today, please let me know (e.g., in the comments).
The main downside of adding these packages is their on-disk size. On cloud instances, adding Mbytes to the base server image can add seconds, or fractions of a second, to instance deployment time. Fortunately the packages I've listed are mostly quite small (and bcc will get smaller) and should cost little size and time. I have seen this size concern prevent debuginfo (totaling around 1 Gbyte) from being included by default.
Can't I just install them later when needed?
Many problems can occur when trying to install software during a production crisis. I'll step through a made-up example that combines some of the things I've learned the hard way:
4:00pm: Alert! Your company's site goes down. No, some people say it's still up. Is it up? It's up but too slow to be usable.
4:01pm: You look at your monitoring dashboards and a group of backend servers are abnormal. Is that high disk I/O? What's causing that?
4:02pm: You SSH to one server to dig deeper, but SSH takes forever to login.
4:03pm: You get a login prompt and type "iostat -xz 1" for basic disk stats to begin with. There is a long pause, and finally "Command 'iostat' not found...Try: sudo apt install sysstat". Ugh. Given how slow the system is, installing this package could take several minutes. You run the install command.
4:07pm: The package install has failed as it can't resolve the repositories. Something is wrong with the /etc/apt configuration. Since the server owners are now in the SRE chatroom to help with the outage, you ask: "how do you install system packages?" They respond "We never do. We only update our app." Ugh. You find a different server and copy its working /etc/apt config over.
4:10pm: You need to run "apt-get update" first with the fixed config, but it's miserably slow.
4:12pm: ...should it really be taking this long??
4:13pm: apt returned "failed: Connection timed out." Maybe this system is too slow with the performance issue? Or can't it connect to the repos? You begin network debugging and ask the server team: "Do you use a firewall?" They say they don't know, ask the network security team.
4:17pm: The network security team have responded: Yes, they have blocked any unexpected traffic, including HTTP/HTTPS/FTP outbound apt requests. Gah. "Can you edit the rules right now?" "It's not that easy." "What about turning off the firewall completely?" "Uh, in an emergency, sure."
4:20pm: The firewall is disabled. You run apt-get update again. It's slow, but works! Then apt-get install, and...permission errors. What!? I'm root, this makes no sense. You share your error in the SRE chatroom and someone points out: Didn't the platform security team make the system immutable?
4:24pm: The platform security team are now in the SRE chatroom explaining that some parts of the file system can be written to, but others, especially for executable binaries, are blocked. Gah! "How do we disable this?" "You can't, that's the point. You'd have to create new server images with it disabled."
4:27pm: By now the SRE team has announced a major outage and informed the executive team, who want regular status updates and an ETA for when it will be fixed. Status: Haven't done much yet.
4:30pm: You start running "cat /proc/diskstats" as a rudimentary iostat(1), but have to spend time reading the Linux source (admin-guide/iostats.rst) to make sense of it. It just confirms the disks are busy which you knew anyway from the monitoring dashboard. You really need the disk and file system tracing tools, like biosnoop(8), but you can't install them either. Unless you can hack up rudimentary tracing tools as well...You "cd /sys/kernel/debug/tracing" and start looking for the FTrace docs.
4:55pm: New server images finally launch with all writable file systems. You login – gee it's fast – and "apt-get install sysstat". Before you can even run iostat there are messages in the chatroom: "Website's back up! Thanks! What did you do?" "We restarted the servers but we haven't fixed anything yet." You have the feeling that the outage will return exactly 10 minutes after you've fallen asleep tonight.
12:50am: Ping! I knew this would happen. You get out of bed and open your work laptop. The site is down – it's been hacked – someone disabled the firewall and file system security.
I've fortunately not experienced the 12:50am event, but the others are based on real world experiences. In my prior job this sequence can often take a different turn: a "traffic team" may initiate a cloud region failover by about the 15 minute mark, so I'd eventually get iostat installed but then these systems would be idle.
Default install
The above scenario explains why you ideally want to pre-install crisis tools so you can start debugging a production issue quickly during an outage. Some companies already do this, and have OS teams that that create custom server images with everything included. But there are many sites still running default versions of Linux that learn this the hard way. I'd recommend Linux distros add these crisis tools to their enterprise Linux variants, so companies large and small can hit the ground running when performance outages occur.
I’ve had a couple of reasons recently to wonder about ipsec: one was doing private overlay networks in confidential VMs and the other was trying to be more efficient than my IPv4 openVPN when I’m remote on an IPv6 capable network. Usually ipsec descriptions begin with tools like raccoon or strong/open/libreswan; however, I’m going to try to explain how you do ipsec at a very basic level within Linux networking stack without using an ipsec toolkit. I’m going to concentrate on my latter use case, so this post is going to be ipsec over IPv6 (although most of the concepts should be applicable to IPv4). To attempt to do this, I’ll be delving into the ip xfrm commands extensively and trying to explain how the transform filters and policy work with the rest of the Linux networking stack.
The basics of ipsec
ipsec has two “protocols”: Authentication Header (AH) which means the packet is fully authenticated (or integrity protected) by an HMAC but not encrypted; and Encapsulating Security Payload (ESP), where the packet is encrypted but not necessarily integrity protected (ipsec was invented before AEAD ciphers, so previously you used both protocols to ensure confidentiality and integrity but, in the modern world, you can use ESP with an AEAD cipher and dispense entirely with AH). Once you have the protocol set, you encapsulate either in transport or tunnel mode. Transport mode means that the protocol headers are simply added to an existing IP packet (so the source and destination address remain the same) in the case of AH and an added header plus an encryption transformed payload with ESP and tunnel mode means that the entire IP packet is encapsulated and a new outer source and destination address is added (this is sometimes referred to as an ipsec VPN).
Understanding ipsec flows
This diagram should help understand how ipsec transforms work. There are two aspects to this: policy which basically does accept/reject and tagging and state, which does the encode/decode
The square boxes are the firewall filters and the ellipses are the ip xfrm policy and state transforms. xfrm decode is unconditionally activated whenever an ipsec packet reaches the input flow (provided there’s a matching state rule), output encoding only occurs if a matching output policy says it should (otherwise the packet is passed unencoded) and the xfrm policy fwd has no matching encode/decode, so it’s not possible to ipsec transform forwarded packets.
ip xfrm policy
To decapsulate, there is no requirement for a policy: every ipsec packet coming into the INPUT flow will be checked for a state match and decapsulated if one is found. However, for the packet to progress further you may need a policy. For transport mode, the decapsulated packet will go back around the input loop, so a dir in policy likely isn’t required but for tunnel mode, the decapsulated packet will likely traverse the FORWARD table and a dir fwd policy plus a firewall rule is likely required to permit the packet. Forwarded packets also hit the dir out policy as well.
A policy is specified with two parts: a selector which contains a set of matches (the only mandatory part of which is the direction dir) and which may match on partial addresses an action (block or allow, with allow being default) and a template (tmpl) which can specify the encoding (for dir out) or additional rules based on encapsulation.
Encoding Templates
Encoding only applies to dir out policies. Transport mode simply requires a statement of which encapsulation to use (proto ah or esp) and doesn’t require IP addresses in the ID section. In tunnel mode, the template must also have the source and destination outer IP addresses (the current source and destination become the inner addresses).
Every packet matching an encoding policy must also have a corresponding ip xfrm state match to specify the encapsulation parameters. Note that if a state transform is missing, the kernel will signal this on a netlink socket (which you can monitor with ip xfrm monitor). This socket is mostly used by ipsec toolkits to add state transforms just in time.
Other Policy Templates
For the in and fwd directions, the template acts as an additional filter on what packets to allow and what to block. For instance, if only decapsulated packets should be forwarded, then there should be a policy like
ip xfrm policy add dst net/netmask dir fwd tmpl proto ah mode tunnel level required
Which says the only allowed packets are those which were encapsulated in tunnel mode. Note that for this policy to be reached at all, the FORWARD table must allow the packets to pass. For most network security people, having a blanket forward permit rule is an anathema, so they often achieve the same thing by applying a firewall mark in decapsulation (the output-mark option of ip xfrm state) and only allowing market packets to pass the FORWARD chain (which dispenses with the need for a xfrm dir fwd policy). The two levers for controlling filter policies are the action (allow or block) the default is allow which is why this statement usually doesn’t appear) and the template level (required or use). The default level is required, which means for the allow rule to match the packet must be decapsulate (level use means pass regardless of decapsulation status)
Security Parameters Index (SPI) and reqid
For ipsec to work, every encapsulated packet must have a SPI value. You can specify this in the state transformation. The standards (RFC2409, RFC4303, etc) specify that SPI values 1-255 are “reserved”. Additionally the standards allow SPI value 0 to be used internally, which the Linux Kernel takes advantage of. SPI is mostly used to distinguish packet streams from the same host for complex ipsec policy, and don’t have much use in a simple policy situation. However, you must provide a value that isn’t 0-255 otherwise strange things can happen. In particular 0, the value you’ll get if you don’t specify spi, often causes the packet to get lost after decapsulation, so always specify a large number for spi. requid is a label which is attached to an unencapsulated packet that effectively remembers what the SPI value was; it’s mostly used as a label based discriminator in policy template to state transforms.
For the purposes of the following example I’ll simply use the randomly chosen 4321 for the spi value (but you could choose anything outside the 0-255 range).
ip xfrm state
Unlike policy, which attaches to a particular location (in, out or fwd), state is location agnostic and the same state match could theoretically be used both to encapsulate or decapsulate. State matching also isn’t subnet based: the address matching is either exact or fully wild card (match everything). However, a state encapsulation transform rule must match on dst and a decapsulation one may match on either src or dst, but must have an exact match on one or other. The main thing the state specifies is the algorithm to encapsulate (see man ip-xfrm for a full list). Remember you also must specify spi. The only other thing you might want to specify is the sel parameter. The selector applies to the inner address of decapsulated packets and is to ensure that a mode tunnel packet is going to an address you approve of.
Simple Example: HMAC authentication between two nodes
Assume a [4321::]/64 subnet with two nodes [4321::1] and [4321::2]. To set up authenticated headers one way (from 1->2) you need a policy specifying AH (can be specific or subnet based, so this is subnet)
ip xfrm policy add dst 4321::/64 dir out tmpl proto ah mode tunnel
Followed by a state that’s specific to the destination (using random spi 4321 and short key 1234):
ip xfrm state add dst 4321::2 proto ah spi 4321 auth "hmac(sha1)" 1234 mode transport
If you ping from [4321::1] and do a tcp dump from [4321::2] you’ll see
But nothing will come back until you add on [4321::2]
ip xfrm state add dst 4321::2 proto ah spi 4321 auth "hmac(sha1)" 1234 mode transport
Which will cause a ping response to be seen. Note the ping packet has an authentication header, but the response is a simple icmp6 response packet (no AH) demonstrating ipsec can be set up asymmetrically.
Example: Private network for Cloud Nodes
Assume we have N nodes with public IP addresses [4321::1]…[4321::N] (which could be provided by the cloud overlay or simply by virtue of the physical network the nodes are on) and we want to connect them in a private mesh network using encryption. There are two ways of doing this: the first is to encrypt all traffic between the nodes on the public network using transport mode and the second would be to set up overlay tunnels between the nodes (this latter can be used even if the public addresses aren’t on a single network segment).
Simple Transport Mode Encryption
Firstly each node needs a policy to require encryption both to and from the private network
ip xfrm policy add dst 4321::0/64 dir out tmpl proto esp
ip xfrm policy add scr 4321::/64 dir in tmpl proto esp
And then for each node on the star and encrypt and a decrypt policy (the aes cipher type is taken from the key length, so I’ve chosen a 128 bit key “1234567890123456”)
ip xfrm state add dst 4321::1 proto esp spi 4321 enc "cbc(aes)" 1234567890123456 mode transport
ip xfrm state add src 4321::1 proto esp sip 4321 enc "cbc(aes)" 1234567890123456 mode transport
...
ip xfrm state add dst 4321::N proto esp spi 4321 enc "cbc(aes)" 1234567890123456 mode transport
ip xfrm state add src 4321::N proto esp sip 4321 enc "cbc(aes)" 1234567890123456 mode transport
This encryption scheme has one key for the entire network, but you could use 1 key per node if you wished (although this wouldn’t necessarily increase security that much). Note that what’s described above is not an overlay network because it relies on using the characteristics of the underlying network (in this case that all nodes are on an IPv6 /64 segment) to do opportunistic transport encryption. To get a true single subnet overlay on top of a disjoint network there must be some sort of tunnel. One way to get the tunnel is simply to use ipsec in tunnel mode, but another is to set up gre tunnels (or another, not necessarily trusted, network overlay which the cloud can likely provide) for the virtual overlay and then use ipsec in transport mode to ensure the packets are always encrypted.
Tunnel Mode Overlay Network
For this example, we’ll allow unencrypted packets to flow over a routed network [4321::1] and [4322::2] (assume network device eth0 on each node) but set up an overlay network on [6666::N]/64 which is fully encrypted. Firstly, each node requires a local address addition for the [6666::N] address. So on node [4321::1] do
ip addr add 6666::1/128 dev eth0
Now add policies and state transforms in both directions (in this case a dir in policy is required otherwise the decapsulated packets won’t get sent up the input flow):
# required policy for encapsulation
ip xfrm policy add dst 6666::2 dir out tmpl src 4321::1 dst 4322::2 proto esp mode tunnel
# state transform for encapsulation
ip xfrm state add src 4321::1 dst 4322::2 proto esp spi 4321 enc "cbc(aes)" 1234567890123456 mode tunnel
# policy to allow passing of decapsulated packets
ip xfrm policy add dst 6666::1 dir in tmpl proto esp mode tunnel level required
# automatic decapsulation. sel ensures addresses after decapsulation
ip xfrm state add src 4322::2 dst 4321::1 proto esp sip 4321 enc "cbc(aes)" 1234567890123456 mode tunnel sel src 6666::2 dst 6666::1
And on the other node [4322::2] do the same in reverse
ip addr add 6666::2/128 dev eth0
ip xfrm policy add dst 6666::1 dir out tmpl src 4321::1 dst 4322::2 proto esp mode tunnel
ip xfrm state add src 4322::2 dst 4321::1 proto esp spi 4321 enc "cbc(aes)" 1234567890123456 mode tunnel
ip xfrm policy add dst 6666::2 dir in tmpl proto esp mode tunnel level required
ip xfrm state add src 4321::1 dst 4322::2 proto esp sip 4321 enc "cbc(aes)" 1234567890123456 mode tunnel sel src 6666::1 dst 6666::2
Note there’s no need to add any routing entries because the decapsulation is point to point (incoming decapsulated packets always end up in the input flow destined for the local [6666::N] address). With the above rules you should be able to ping from [6666::1] to [6666::2] and tcpdump should show fully encrypted packets going over the wire.
Obviously, you can add more nodes but each time you have to add rules for all the other nodes, making this an N(N-1) scaling problem. The need for a specific source and destination template in the out policy means you must have one for each connection. The in policy can be subnet based. The reason why people use ipsec toolkits is that they can add the transforms just in time for the subset of nodes you’re actually communicating with rather than having to add all the rules up front.
Final Example: correcly keyed AH Inbound Packet Acceptance
The final example is me trying to penetrate my router firewall when on an external IPv6 connection. I have a class /60 set of IPv6 space, so each of my systems has its own IPv6 address but, as is usual, inbound packets in the NEW state are blocked. It occurred to me that I should be able to use ipsec AH (no real need for encryption since most of the protocols I use are encrypted anyway) to accept packets to an internal destination with the NEW state. This would be an asymmetric use of ipsec because inbound would have AH but return wouldn’t.
My initial thought was to use AH in transport mode, but as you can see from the diagram above that won’t work because the router merely forwards the packets and to get to a state decapsulation on the router they have to go up the INPUT flow.
The next attempt used tunnel mode, so the packet was aimed at the router and then the inner destination was the real node. The next problem was the fwd policy to permit this: the xfrm policy has no connection tracker and return packets from connections originating in the interior node also have to pass this filter. The solution to this conundrum is to install a level use policy and rely on the FORWARD table firewall rules to allow RELATED,ESTABLISHED and MARKed packets (so the decapsulation can add the MARK to pass this rule).
IPSEC on the Router
Assume my external router address is [4321::1] and my internal network is [4444::]/60. On the router, I install a catch all state transform
ip xfrm state add add dst 4321::1 proto ah spi 4321 auth "hmac(sha1)" 1234 mode tunnel sel dst 4444::/60 output-mark 0x1
But I also need a policy to permit the decapsulated packets (and the state RELATED,ESTABLISHED unencapsulated ones) to pass:
ip xfrm policy add dst 4444::/60 dir fwd tmpl proto ah spi 4321 mode tunnel level use
And finally I need an addition to the firewall rules to allow packets in state NEW but with mark 0x1 to pass
ip6tables -A FORWARD -m conntrack --ctstate NEW -m mark --mark 0x1/0x1 -j ACCEPT
Which should be placed directly after the RELATED,ESTABLISHED state check.
Since there’s no encapsulation on outbound, the return packets simply pass through the firewall as normal. This means that any external entity wishing to use this AH packet acceptance simply needs a policy and state to tunnel
ip xfrm policy dst 4444::/60 dir out tmpl proto ah dst 4321::1 mode tunnel
ip xfrm state add dst 4321::1 spi 4321 proto ah auth "hmac(sha1)" 1234 mode tunnel
And with that, any machine known by inner IPv6 address can be reached (for an IPv6 connected remote machine).
Conclusion
Hopefully this post has demystified some of the ip xfrm rules for you. I’m afraid the commands have a huge range of options, so I’ve only covered the essential ones above and there are still loads of interesting but not at all well documented ones remaining, but thanks to the examples you should have some scope now for playing with them.
Linux Plumbers Conference 2024 is pleased to host the eBPF Track!
After four years in a row of co-locating eBPF & Networking Tracks together, this year we separated the two in order to allow for both tracks to grow further individually as well as to bring more diversity into LPC by attracting more developers from each community.
The eBPF Track is going to bring together developers, maintainers, and other contributors from all around the globe to discuss improvements to the Linux kernel’s BPF subsystem and its surrounding user space ecosystem such as libraries, loaders, compiler backends, and other related low-level system tooling.
The gathering is designed to foster collaboration and face to face discussion of ongoing development topics as well as to encourage bringing new ideas into the development community for the advancement of the BPF subsystem.
Proposals can cover a wide range of topics related to BPF covering improvements in areas such as (but not limited to) BPF infrastructure and its use in tracing, security, networking, scheduling and beyond, as well as non-kernel components like libraries, compilers, testing infra and tools.
Please come and join us in the discussion. We hope to see you there!
Sometimes debuggers and profilers are obviously broken, sometimes it's subtle and hard to spot. From my flame graphs page:
CPU flame graph (partly broken)
(Click for original SVG.) This is pretty common and usually goes unnoticed as the flame graph looks ok at first glance. But there are 15% of samples on the left, above "[unknown]", that are in the wrong place and missing frames. The problem is that this system has a default libc that has been compiled without frame pointers, so any stack walking stops at the libc layer, producing a partial stack that's missing the application frames. These partial stacks get grouped together on the left.
Click here for a longer explanation.
To explain this example in more detail: The profiler periodically interrupts software execution, and for those disconnected stacks it happens to be the execution of the kernel software ("vfs*", "ext*", etc.). Once interrupted, the profiler begins at the top edge of the flame graph (or bottom edge if you are using the icicle layout) and then "stack walks" down through the rectangles to collect a stack trace. It finally gets through the kernel frames then steps through the syscall (sys_write()) to userspace, hits the libc syscall wrapper (__GI___libc_write()), then tries to resolve the symbol for the next frame but fails and records "[unknown]". It fails because of a compiler optimization where the frame pointer register is used to store data instead of the frame pointer, but it's just a number so the profiler is unaware this happened and tries to match that address to a function symbol and fails (it is therefore an unknown symbol). Then, the profiler is usually unable to walk any more frames because that data doesn't point to the next frame either (and likely doesn't point to any valid mapping, because to the profiler it's effectively a random number), so it stops before it can reach the application frames. There's probably several frames missing from that left disconnected tower, similar to the application frames you see on the right (this example happens to be the bash(1) shell). What happens if the random data is a valid pointer by coincidence? You usually get an extra junk frame. I've seen situations where the random data ends up pointing to itself, so the profiler gets stuck in a loop and you get a tower of junk frames until perf hits its max frame limit.
Other types of profiling hit this more often. Off-CPU flame graphs, for example, can be dominated by libc read/write and mutex functions, so without frame pointers end up mostly broken. Apart from library code, maybe your application doesn't have frame pointers either, in which case everything is broken.
I'm posting about this problem now because Fedora and Ubuntu are releasing versions that fix it, by compiling libc and more with frame pointers by default. This is great news as it not only fixes these flame graphs, but makes off-CPU flame graphs far more practical. This is also a win for continuous profilers (my employer, Intel, just announced one) as it makes customer adoption easier.
What are frame pointers?
The x86-64 ABI documentation shows how a CPU register, %rbp, can be used as a "base pointer" to a stack frame, aka the "frame pointer." I pictured how this is used to walk stack traces in my BPF book.
Figure 3.3: Stack Frame with Base Pointer (x86-64 ABI)
This stack-walking technique is commonly used by external profilers and debuggers, including Linux perf and eBPF, and ultimately visualized by flame graphs. However, the x86-64 ABI has a footnote [12] to say that this register use is optional:
"The conventional use of %rbp as a frame pointer for the stack frame may be avoided by using %rsp
(the stack pointer) to index into the stack frame. This technique saves two instructions in the prologue and
epilogue and makes one additional general-purpose register (%rbp) available."
(Trivia: I had penciled the frame pointer function prologue and epilogue on my Netflix office wall, lower left.)
2004: Their removal
In 2004 a compiler developer, Roger Sayle, changed gcc to stop generating frame pointers, writing:
"The simple patch below tweaks the i386 backend, such that we now
default to the equivalent of "-fomit-frame-pointer -ffixed-ebp" on
32-bit targets"
i386 (32-bit microprocessors) only have four general purpose registers, so freeing up %ebp takes you from four to five (or if you include %si and %di, from six to seven). I'm sure this delivered large performance improvements and I wouldn't try arguing against it. Roger cited two other reasons for this change: The desire to outperform Intel's icc compiler, and the belief that it didn't break debuggers (of the time) since they supported other stack walking techniques.
2005-2023: The winter of broken profilers
However, the change was then applied to x86-64 (64-bit) as well, which had over a dozen registers and didn't benefit so much from freeing up one more. And there are debuggers/profilers that this change did break (typically system profilers, not language specific ones), more so today with eBPF, which didn't exist back then. As my former Sun Microsystems colleague Eric Schrock (nickname Schrock) wrote in November 2004:
"On i386, you at least had the advantage of increasing the number of usable registers by 20%. On amd64, adding a 17th general purpose register isn't going to open up a whole new world of compiler optimizations. You're just saving a pushl, movl, an series of operations that (for obvious reasons) is highly optimized on x86. And for leaf routines (which never establish a frame), this is a non-issue. Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway. Given the benefit and the relative cost of losing debuggability, this hardly seems worth it."
In Schrock's conclusion:
"it's when people start compiling /usr/bin/ without frame pointers that it gets out of control."
This is exactly what happened on Linux, not just /usr/bin but also /usr/lib and application code! I'm sure there are people who are too new to the industry to remember the pre-2004 days when profilers would "just work" without OS and runtime changes.
2014: Java in Flames
Broken Java Stacks (2014)
When I joined Netflix in 2014, I found Java's lack of frame pointer support broke all application stacks (pictured in my 2014 Surge talk on the right). I ended up developing a fix for the JVM c2 compiler which Oracle reworked and added as the -XX:+PreserveFramePointer option in JDK8u60 (see my Java in Flames post for details [PDF]).
While that Java change led to discovering countless performance wins in application code, libc was still breaking some portion of the samples (as pictured in the example at the top of this post) and was breaking most stacks in off-CPU flame graphs. I started by compiling my own libc for production use with frame pointers, and then worked with Canonical to have one prebuilt for Ubuntu. For a while I was promoting the use of Canonical's libc6-prof, which was libc6 with frame pointers.
2015-2020: Overhead
As part of production rollout I did many performance overhead tests, which I've described publicly before: The overhead of adding frame pointers to everything (libc and Java) was usually less than 1%, with one exception of 10%. That 10% was an unusual application that was generating stack traces over 1000 frames deep (via Groovy), so deep that it broke Linux's perf profiler. Arnaldo Carvalho de Melo (Red Hat) added the kernel.perf_event_max_stack sysctl just for this Netflix workload. It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based.
The actual overhead depends on your workload. Others have reported around 1% and around 2%. Microbenchmarks can be the worst, hitting 10%: This doesn't surprise me since they resolve to running a small funciton in a loop, and adding any instructions to that function can cause it to spill out of L1 cache warmth (or cache lines) causing a drop in performance. If I were analyzing such a microbenchmark, apart from observability anaylsis (cycles, instructions, PMU, PMCs, PEBS) there is also an experiment I'd like to try:
To test the theory of I-cache spillover: Compile the microbenchmark with and without frame pointers and find the performance delta. Then flame graph the microbenchmark to understand the hot function. Then add some inline assembly to the hot function where you add enough NOPs to the start and end to mimic the frame pointer prologue and epilogue (I recommend writing them on your office wall in pencil), compile it without frame pointers, disassemble the compiled binary to confirm those NOPs weren't stripped, and now test that. If the performance delta is still large (10%) you've confirmed that it is due to cache effects, and anyone who was worked at this level in production will tell you that it's the straw that broke the camel's back. Don't blame the straw, in this case, the frame pointers. Adding anything will cause the same effect. Having done this before, it reminds me of CSS programming: you make a little change here and everything breaks, and you spend hours chasing your own tail.
Another extreme example of overhead was the Python scimark_sparse_mat_mult benchmark, which could reach 10%. Fortunately this was analyzed by Andrii Nakryiko (Meta) who found it was a unusual case of a large function where gcc switched from %rsp offsets to %rbp-relative offsets, which took more bytes to store, causing performance issues. I've heard this has since been fixed so that Python can reenable frame pointers by default.
As I've seen frame pointers help find performance wins ranging from 5% to 500%, the typical "less than 1%" cost (or even 1% or 2% cost) is easily justified. But I'd rather the cost be zero, of course! We may get there with future technologies I'll cover later. In the meantime, frame pointers are the most practical way to find performance wins today.
What about Linux on devices where there is no chance of profiling or debugging, like electric toothbrushes? (I made that up, AFAIK they don't run Linux, but I may be wrong!) Sure, compile without frame pointers. The main users of this change are enterprise Linux. Back-end servers.
2022: Upstreaming, first attempt
Other large companies with OS and perf teams (Meta, Google) hinted strongly that they had already enabled frame pointers for everything years earlier. (Google should be no surprise because they pioneered continuous profiling.) So at this point you had Google, Meta, and Netflix running their own libc with frame pointers and able to enjoy profiling capabilities that most other companies – without dedicated OS teams – couldn't get working. Can't we just upstream this so everyone can benefit?
There's a bunch of difficulties when taking "works well for me" changes and trying to make them the default for everyone. Among the difficulties is that end-user companies don't have a clear return on the investment from telling their Linux vendor what they fixed, since they already fixed it. I guess the investment is quite small, we're talking about a single email, right?...Wrong! Your suggestion is now a 116-post thread where everyone is sharing different opinions and demanding this and that, as we found out the hard way. For Fedora, one person requested:
"Meta and/or Netflix should provide infrastructure for a side repository in which the change can be tested and benchmarked and the code size measured."
(Bear in mind that Netflix doesn't even use Fedora!)
Jonathan Corbet, who writes the best Linux articles, summarized this in "Fedora's tempest in a stack frame" which is so detailed that I feel PTSD when reading it. It's good that the Fedora community wants to be so careful, but I'd rather spend time discussing building something better than frame pointers, perhaps involving ORC, LBR, eBPF, and other technologies, than so much worry about looking bad in kitchen-sink benchmarks that I wouldn't trust in the first place.
2023, 2024: Frame Pointers in Fedora and Ubuntu!
Fedorarevisited the proposal and has accepted it this time, making it the first distro to reenable frame pointers. Thank you!
UPDATE: I've now heard that Arch Linux is also enabling frame pointers! Thanks Daan De Meyer (Meta).
While this fixes stack walking through OS libraries, you might find your application still doesn't support stack tracing, but that's typically much easier to fix. Java, for example, has the -XX:+PreserveFramePointer option. There were ways to get Golang to support frame pointers, but that became the default years ago. Just to name a couple of languages.
2034+: Beyond Frame Pointers
There's more than one way to walk a stack. These could be separate blog posts, but I want to comment briefly on alternates:
LBR (Last Branch Record): Intel's hardware feature that was limited to 16 or 32 frames. Most application stacks are deeper, so this can't be used to build flame graphs, but it is better than nothing. I use it as a last resort as it gives me some stack insights.
BTS (Branch Trace Store): Another Intel thing. Not so limited to stack depth, but has overhead from memory load/stores and BTS buffer overflow interrupt handling.
AET (Archetectural Event Trace): Another Intel thing. It's a JTAG-based tracer that can trace low-level CPU, BIOS, and device events, and apparently can be used for stack traces as well. I haven't used it. (I spent years as a cloud customer where I couldn't access many HW-level things.) I hope it can be configured to output to main memory, and not just a physical debug port.
DWARF: Binary debuginfo, has been used forever with debuggers. Update: I'd said it doesn't exist for JIT'd runtimes like the Java JVM, but others have pointed out there has been some JIT->DWARF work done. I still don't expect it to be practical on busy production servers that are constantly in c2. The overhead just to walk DWARF is also high, as it was designed for non-realtime use. Javier Honduvilla Coto (Polar Signals) did some interesting work using an eBPF walker to reduce the overhead, but...Java.
eBPF stack walking: Mark Wielaard (Red Hat) demonstrated a Java JVM stack walker using SystemTap back at LinuxCon 2014, where an external tracer walked a runtime with no runtime support or help. Very cool. This can be done using eBPF as well. The performmance overhead could be too high, however, as it may mean a lot of user space reads of runtime internals depending on the runtime. It would also be brittle; such eBPF stack walkers should ship with the language code base and be maintained with it.
ORC (oops rewind capability): The Linux kernel's new lightweight stack unwinder by Josh Poimboeuf (Red Hat) that has allowed newer kernels to remove frame pointers yet retain stack walking. You may be using ORC without realizing it; the rollout was smooth as the kernel profiler code was updated to support ORC (perf_callchain_kernel()->unwind_orc.c) at the same time as it was compiled to support ORC. Can't ORCs invade user space as well?
SFrames (Stack Frames): ...which is what SFrames does: lightweight user stack unwinding based on ORC. There have been recent talks to explain them by Indu Bhagat (Oracle) and Steven Rostedt (Google). I should do a blog post just on SFrames.
Shadow Stacks: A newer Intel and AMD security feature that can be configured to push function return addresses onto a separate HW stack so that they can be double checked when the return happens. Sounds like such a HW stack could also provide a stack trace, without frame pointers.
(And this isn't even all of them.)
Daan De Meyer (Meta) did a nice summary as well of different stack walkers on the Fedora wiki.
So what's next? Here's my guesses:
2029: Ubuntu and Fedora release new versions with SFrames for OS components (including libc) and ditches frame pointers again. We'll have had five years of frame pointer-based performance wins and new innovations that make use of user space stacks (e.g., better automated bug reporting), and will hit the ground running with SFrames.
2034: Shadow stacks have been enabled by default for security, and then are used for all stack tracing.
Conclusion
I could say that times have changed and now the original 2004 reasons for omitting frame pointers are no longer valid in 2024. Those reasons were that it improved performance significantly on i386, that it didn't break the debuggers of the day (prior to eBPF), and that competing with another compiler (icc) was deemed important. Yes, times have indeed changed. But I should note that one engineer, Eric Schrock, claimed that it didn't make sense back in 2004 either when it was applied to x86-64, and I agree with him. Profiling has been broken for 20 years and we've only now just fixed it.
Fedora and Ubuntu have now returned frame pointers, which is great news. People should start running these releases in 2024 and will find that CPU flame graphs make more sense, Off-CPU flame graphs work for the first time, and other new things become possible. It's also a win for continuous profilers, as they don't need to convince their customers to make OS changes to get profiles to fully work.
Thanks
The online threads about this change aren't even everything, there have been many discussions, meetings, and work put into this, not just for frame pointers but other recent advances including ORC and SFrames. Special thanks to Andrii Nakryiko (Meta), Daan De Meyer (Meta), Davide Cavalca (Meta), Ian Rogers (Google), Steven Rostedt (Google), Josh Poimboeuf (Red Hat), Arjan Van De Ven (Intel), Indu Bhagat (Oracle), Mark Shuttleworth (Canonical), Jon Seager (Canonical), Oliver Smith (Canonical), Javier Honduvilla Coto (Polar Signals), Mark Wielaard (Red Hat), Ben Cotton (Red Hat), and many others (see the Fedora discussions). And thanks to Schrock.
Appendix: Fedora
For reference, here's my writeup for the Fedora change:
I enabled frame pointers at Netflix, for Java and glibc, and summarized the effect in BPF Performance Tools (page 40):
"Last time I studied the performance gain from frame pointer omission in our production environment, it was usually less than one percent, and it was often so close to zero that it was difficult to measure. Many microservices at Netflix are running with the frame pointer reenabled, as the performance wins found by CPU profiling outweigh the tiny loss of performance."
I've spent a lot of time analyzing frame pointer performance, and I did the original work to add them to the JVM (which became -XX:+PreserveFramePoiner). I was also working with another major Linux distro to make frame pointers the default in glibc, although I since changed jobs and that work has stalled. I'll pick it up again, but I'd be happy to see Fedora enable it in the meantime and be the first to do so.
We need frame pointers enabled by default because of performance. Enterprise environments are monitored, continuously profiled, and analyzed on a regular basis, so this capability will indeed be put to use. It enables a world of debugging and new performance tools, and once you find a 500% perf win you have a different perspective about the <1% cost. Off-CPU flame graphs in particular need to walk the pthread functions in glibc as most blocking paths go through them; CPU flame graphs need them as well to reconnect the floating glibc tower of futex/pthread functions with the developers code frames.
I see the comments about benchmark results of up to 10% slowdowns. It's good to look out for regressions, although in my experience all benchmarks are wrong or deeply misleading. You'll need to do cycle analysis (PEBS-based) to see where the extra cycles are, and if that makes any sense. Benchmarks can be super sensitive to degrading a single hot function (like "CPU benchmarks" that really just hammer one function in a loop), and if extra instructions (function prologue) bump it over a cache line or beyond L1 cache-warmth, then you can get a noticeable hit. This will happen to the next developer who adds code anyway (assuming such a hot function is real world) so the code change gets unfairly blamed. It will only regress in this particular scenario, and regression is inevitable. Hence why you need the cycle analysis ("active benchmarking") to make sense of this.
There was one microservice that was an outlier and had a 10% performance loss with Java frame pointers enabled (not glibc, I've never seen a big loss there). 10% is huge. This was before PMCs were available in the cloud, so I could do little to debug it. Initially the microservice ran a "flame graph canary" instance with FPs for flame graphs, but the developers eventually just enabled FPs across the whole microservice as the gains they were finding outweighed the 10% cost. This was the only noticeable (as in, >1%) production regression we saw, and it was a microservice that was bonkers for a variety of reasons, including stack traces that were over 1000 frames deep (and that was after inlining! Over 3000 deep without. ACME added the perf_event_max_stack sysctl just so Netflix could profile this microservice, as the prior limit was 128). So one possibility is that the extra function prologue instructions add up if you frequently walk 1000 frames of stack (although I still don't entirely buy it). Another attribute was that the microservice had over 1 Gbyte of instruction text (!), and we may have been flying close to the edge of hardware cache warmth, where adding a bit more instructions caused a big drop. Both scenarios are debuggable with PMCs/PEBS, but we had none at the time.
So while I think we need to debug those rare 10%s, we should also bear in mind that customers can recompile without FPs to get that performance back. (Although for that microservice, the developers chose to eat the 10% because it was so valuable!) I think frame pointers should be the default for enterprise OSes, and to opt out if/when necessary, and not the other way around. It's possible that some math functions in glibc should opt out of frame pointers (possibly fixing scimark, FWIW), but the rest (especially pthread) needs them.
In the distant future, all runtimes should come with an eBPF stack walker, and the kernel should support hopping between FPs, ORC, LBR, and eBPF stack walking as necessary. We may reach a point where we can turn off FPs again. Or maybe that work will never get done. Turning on FPs now is an improvement we can do, and then we can improve it more later.
For some more background: Eric Schrock (my former colleague at Sun Microsystems) described the then-recent gcc change in 2004 as "a dubious optimization that severely hinders debuggability" and that "it's when people start compiling /usr/bin/* without frame pointers that it gets out of control" I recommend reading his post: [0].
The original omit FP change was done for i386 that only had four general-purpose registers and saw big gains freeing up a fifth, and it assumed stack walking was a solved problem thanks to gdb(1) without considering real-time tracers, and the original change cites the need to compete with icc [1]. We have a different circumstance today -- 18 years later -- and it's time we updated this change.
[0] http://web.archive.org/web/20131215093042/https://blogs.oracle.com/eschrock/entry/debugging_on_amd64_part_one
[1] https://gcc.gnu.org/ml/gcc-patches/2004-08/msg01033.html
Closing arguments in the trial between various people and Craig Wright over whether he's Satoshi Nakamoto are wrapping up today, amongst a bewildering array of presented evidence. But one utterly astonishing aspect of this lawsuit is that expert witnesses for both sides agreed that much of the digital evidence provided by Craig Wright was unreliable in one way or another, generally including indications that it wasn't produced at the point in time it claimed to be. And it's fascinating reading through the subtle (and, in some cases, not so subtle) ways that that's revealed.
One of the pieces of evidence entered is screenshots of data from Mind Your Own Business, a business management product that's been around for some time. Craig Wright relied on screenshots of various entries from this product to support his claims around having controlled meaningful number of bitcoin before he was publicly linked to being Satoshi. If these were authentic then they'd be strong evidence linking him to the mining of coins before Bitcoin's public availability. Unfortunately the screenshots themselves weren't contemporary - the metadata shows them being created in 2020. This wouldn't fundamentally be a problem (it's entirely reasonable to create new screenshots of old material), as long as it's possible to establish that the material shown in the screenshots was created at that point. Sadly, well.
One part of the disclosed information was an email that contained a zip file that contained a raw database in the format used by MYOB. Importing that into the tool allowed an audit record to be extracted - this record showed that the relevant entries had been added to the database in 2020, shortly before the screenshots were created. This was, obviously, not strong evidence that Craig had held Bitcoin in 2009. This evidence was reported, and was responded to with a couple of additional databases that had an audit trail that was consistent with the dates in the records in question. Well, partially. The audit record included session data, showing an administrator logging into the data base in 2011 and then, uh, logging out in 2023, which is rather more consistent with someone changing their system clock to 2011 to create an entry, and switching it back to present day before logging out. In addition, the audit log included fields that didn't exist in versions of the product released before 2016, strongly suggesting that the entries dated 2009-2011 were created in software released after 2016. And even worse, the order of insertions into the database didn't line up with calendar time - an entry dated before another entry may appear in the database afterwards, indicating that it was created later. But even more obvious? The database schema used for these old entries corresponded to a version of the software released in 2023.
This is all consistent with the idea that these records were created after the fact and backdated to 2009-2011, and that after this evidence was made available further evidence was created and backdated to obfuscate that. In an unusual turn of events, during the trial Craig Wright introduced further evidence in the form of a chain of emails to his former lawyers that indicated he had provided them with login details to his MYOB instance in 2019 - before the metadata associated with the screenshots. The implication isn't entirely clear, but it suggests that either they had an opportunity to examine this data before the metadata suggests it was created, or that they faked the data? So, well, the obvious thing happened, and his former lawyers were asked whether they received these emails. The chain consisted of three emails, two of which they confirmed they'd received. And they received a third email in the chain, but it was different to the one entered in evidence. And, uh, weirdly, they'd received a copy of the email that was submitted - but they'd received it a few days earlier. In 2024.
And again, the forensic evidence is helpful here! It turns out that the email client used associates a timestamp with any attachments, which in this case included an image in the email footer - and the mysterious time travelling email had a timestamp in 2024, not 2019. This was created by the client, so was consistent with the email having been sent in 2024, not being sent in 2019 and somehow getting stuck somewhere before delivery. The date header indicates 2019, as do encoded timestamps in the MIME headers - consistent with the mail being sent by a computer with the clock set to 2019.
But there's a very weird difference between the copy of the email that was submitted in evidence and the copy that was located afterwards! The first included a header inserted by gmail that included a 2019 timestamp, while the latter had a 2024 timestamp. Is there a way to determine which of these could be the truth? It turns out there is! The format of that header changed in 2022, and the version in the email is the new version. The version with the 2019 timestamp is anachronistic - the format simply doesn't match the header that gmail would have introduced in 2019, suggesting that an email sent in 2022 or later was modified to include a timestamp of 2019.
This is by no means the only indication that Craig Wright's evidence may be misleading (there's the whole argument that the Bitcoin white paper was written in LaTeX when general consensus is that it's written in OpenOffice, given that's what the metadata claims), but it's a lovely example of a more general issue.
Our technology chains are complicated. So many moving parts end up influencing the content of the data we generate, and those parts develop over time. It's fantastically difficult to generate an artifact now that precisely corresponds to how it would look in the past, even if we go to the effort of installing an old OS on an old PC and setting the clock appropriately (are you sure you're going to be able to mimic an entirely period appropriate patch level?). Even the version of the font you use in a document may indicate it's anachronistic. I'm pretty good at computers and I no longer have any belief I could fake an old document.
(References: this Dropbox, under "Expert reports", "Patrick Madden". Initial MYOB data is in "Appendix PM7", further analysis is in "Appendix PM42", email analysis is "Sixth Expert Report of Mr Patrick Madden")
In a different epoch, before the pandemic, I’ve done a presentation about
upstream first at the Siemens Linux Community
Event 2018, where I’ve tried to explain the fundamentals of open source using
microeconomics. Unfortunately that talk didn’t work out too well with an
audience that isn’t well-versed in upstream and open source concepts, largely
because it was just too much material crammed into too little time.
Last year I got the opportunity to try again for an Intel-internal event series,
and this time I’ve split the material into two parts. I think that worked a lot
better. For obvious reasons I cannot publish the recordings, but I can publish
the slides.
The first part “Upstream, Why?” covers a
few concepts from microeconomcis 101, and then applies them to upstream stream
open source. The key concept is on one hand that open source achieves an
efficient software market in the microeconomic sense by driving margins and
prices to zero. And the only way to make money in such a market is to either
have more-or-less unstable barriers to entry that prevent the efficient market
from forming and destroying all monetary value. Or to sell a complementary
product.
Individual engineers, who have skills and create a product with zero economic
value, and might still be stupid enough and try to build a career on that.
Upstream communities, often with a formal structure as a foundation, and what
exactly their goals should be to build a thriving upstream open source project
that can actually pay some bills, generate some revenue somewhere else and get
engineers paid. Because without that you’re not going to have much of a
project with a long term future.
Engineering organizations, what exactly their incentives and goals should
be, and the fundamental conflicts of interest this causes. Specifically on
this I’ve only seen bad solutions, and ugly solutions, but not yet a really
good one. A relevant pre-pandemic talk of mine on this topic is also
“Upstream Graphics: Too Little, Too
Late”
And finally the overall business and more importantly, what kind of business
strategy is needed to really thrive with an open source upstream first
approach: You need to clearly understand which software market’s economic
value you want to destroy by driving margins and prices to zero, and which
complemenetary product you’re selling to still earn money.
At least judging by the feedback I’ve received internally taking more time and
going a bit more in-depth on the various concept worked much better than the
keynote presentation I’ve done at Siemens, hence I decided to publish at the
least the slides.
eBPF is a crazy technology – like putting JavaScript into the Linux kernel – and getting it accepted had so far been an untold story of strategy and ingenuity. The eBPF documentary, published late last year, tells this story by interviewing key players from 2014 including myself, and touches on new developments including Windows. (If you are new to eBPF, it is the name of a kernel execution engine that runs a variety of new programs in a performant and safe sandbox in the kernel, like how JavaScript can run programs safely in a browser sandbox; it is also no longer an acronym.) The documentary was played at KubeCon and is on youtube:
Watching this brings me right back to 2014, to see the faces and hear their voices discussing the problems we were trying to fix. Thanks to Speakeasy Productions for doing such a great job with this documentary, and letting you experience what it was like in those early days. This is also a great example of all the work that goes on behind the scenes to get code merged in a large codebase like Linux.
When Alexei Starovoitov visited Netflix in 2014 to discuss eBPF with myself and Amer Ather, we were so entranced that we lost track of time and were eventually kicked out of the meeting room as another meeting was starting. It was then I realized that we had missed lunch! Alexei sounded so confident that I was convinced that eBPF was the future, but a couple of times he added "if the patches get merged." If they get merged?? They have to get merged, this idea is too good to waste.
While only several of us worked on eBPF in 2014, more joined in 2015 and later, and there are now hundreds contributing to make it what it is. A longer documentary could also interview Brendan Blanco (bcc), Yonghong Song (bcc), Sasha Goldshtein (bcc), Alastair Robertson (bpftrace), Tobais Waldekranz (ply), Andrii Nakryiko, Joe Stringer, Jakub Kicinski, Martin KaFai Lau, John Fastabend, Quentin Monnet, Jesper Dangaard Brouer, Andrey Ignatov, Stanislav Fomichev, Teng Qin, Paul Chaignon, Vicent Marti, Dan Xu, Bas Smit, Viktor Malik, Mary Marchini, and many more. Thanks to everyone for all the work.
Ten years later it still feels like it's early days for eBPF, and a great time to get involved: It's likely already available in your production kernels, and there are tools, libraries, and documentation to help you get started.
I hope you enjoy the documentary. PS. Congrats to Isovalent, the role-model eBPF startup, as Cisco recently announced they would acquire them!
Linux Plumbers Conference 2024 is pleased to host the Toolchains Track!
The aim of the Toolchains track is to fix particular toolchain issues which are of the interest of the kernel and, ideally, find solutions in situ, making the best use of the opportunity of live discussion with kernel developers and maintainers. In particular, this is not about presenting research nor abstract/miscellaneous toolchain work.
The track will be composed of activities, of variable length depending on the topic being discussed. Each activity is intended to cover a particular topic or issue involving both the Linux kernel and one or more of its associated toolchains and development tools. This includes compiling, linking, assemblers, debuggers and debugging formats, ABI analysis tools, object manipulation, etc. Few slides shall be necessary, and most of the time shall be devoted to actual discussion, brainstorming and seeking agreement.
Please come and join us in the discussion. We hope to see you there!
Following generic guides (e.g. at Akamai Linode) almost got it all working with ease. There were a few minor problems with permissions.
Problem: Feb 28 11:45:17 takane postfix/smtpd[1137214]: warning: connect to Milter service local:/run/opendkim/opendkim.sock: Permission denied Solution: add postfix to opendkim group; no change to Umask etc.
Problem: Feb 28 13:36:39 takane opendkim[1136756]: 5F1F4DB81: no signing table match for 'zaitcev@kotori.zaitcev.us' Solution: change SigningTable from refile: to a normal file
We have a cabin out in the forest, and when I say "out in the forest" I mean "in a national forest subject to regulation by the US Forest Service" which means there's an extremely thick book describing the things we're allowed to do and (somewhat longer) not allowed to do. It's also down in the bottom of a valley surrounded by tall trees (the whole "forest" bit). There used to be AT&T copper but all that infrastructure burned down in a big fire back in 2021 and AT&T no longer supply new copper links, and Starlink isn't viable because of the whole "bottom of a valley surrounded by tall trees" thing along with regulations that prohibit us from putting up a big pole with a dish on top. Thankfully there's LTE towers nearby, so I'm simply using cellular data. Unfortunately my provider rate limits connections to video streaming services in order to push them down to roughly SD resolution. The easy workaround is just to VPN back to somewhere else, which in my case is just a Wireguard link back to San Francisco.
This worked perfectly for most things, but some streaming services simply wouldn't work at all. Attempting to load the video would just spin forever. Running tcpdump at the local end of the VPN endpoint showed a connection being established, some packets being exchanged, and then… nothing. The remote service appeared to just stop sending packets. Tcpdumping the remote end of the VPN showed the same thing. It wasn't until I looked at the traffic on the VPN endpoint's external interface that things began to become clear.
This probably needs some background. Most network infrastructure has a maximum allowable packet size, which is referred to as the Maximum Transmission Unit or MTU. For ethernet this defaults to 1500 bytes, and these days most links are able to handle packets of at least this size, so it's pretty typical to just assume that you'll be able to send a 1500 byte packet. But what's important to remember is that that doesn't mean you have 1500 bytes of packet payload - that 1500 bytes includes whatever protocol level headers are on there. For TCP/IP you're typically looking at spending around 40 bytes on the headers, leaving somewhere around 1460 bytes of usable payload. And if you're using a VPN, things get annoying. In this case the original packet becomes the payload of a new packet, which means it needs another set of TCP (or UDP) and IP headers, and probably also some VPN header. This still all needs to fit inside the MTU of the link the VPN packet is being sent over, so if the MTU of that is 1500, the effective MTU of the VPN interface has to be lower. For Wireguard, this works out to an effective MTU of 1420 bytes. That means simply sending a 1500 byte packet over a Wireguard (or any other VPN) link won't work - adding the additional headers gives you a total packet size of over 1500 bytes, and that won't fit into the underlying link's MTU of 1500.
And yet, things work. But how? Faced with a packet that's too big to fit into a link, there are two choices - break the packet up into multiple smaller packets ("fragmentation") or tell whoever's sending the packet to send smaller packets. Fragmentation seems like the obvious answer, so I'd encourage you to read Valerie Aurora's article on how fragmentation is more complicated than you think. tl;dr - if you can avoid fragmentation then you're going to have a better life. You can explicitly indicate that you don't want your packets to be fragmented by setting the Don't Fragment bit in your IP header, and then when your packet hits a link where your packet exceeds the link MTU it'll send back a packet telling the remote that it's too big, what the actual MTU is, and the remote will resend a smaller packet. This avoids all the hassle of handling fragments in exchange for the cost of a retransmit the first time the MTU is exceeded. It also typically works these days, which wasn't always the case - people had a nasty habit of dropping the ICMP packets telling the remote that the packet was too big, which broke everything.
What I saw when I tcpdumped on the remote VPN endpoint's external interface was that the connection was getting established, and then a 1500 byte packet would arrive (this is kind of the behaviour you'd expect for video - the connection handshaking involves a bunch of relatively small packets, and then once you start sending the video stream itself you start sending packets that are as large as possible in order to minimise overhead). This 1500 byte packet wouldn't fit down the Wireguard link, so the endpoint sent back an ICMP packet to the remote telling it to send smaller packets. The remote should then have sent a new, smaller packet - instead, about a second after sending the first 1500 byte packet, it sent that same 1500 byte packet. This is consistent with it ignoring the ICMP notification and just behaving as if the packet had been dropped.
All the services that were failing were failing in identical ways, and all were using Fastly as their CDN. I complained about this on social media and then somehow ended up in contact with the engineering team responsible for this sort of thing - I sent them a packet dump of the failure, they were able to reproduce it, and it got fixed. Hurray!
(Between me identifying the problem and it getting fixed I was able to work around it. The TCP header includes a Maximum Segment Size (MSS) field, which indicates the maximum size of the payload for this connection. iptables allows you to rewrite this, so on the VPN endpoint I simply rewrote the MSS to be small enough that the packets would fit inside the Wireguard MTU. This isn't a complete fix since it's done at the TCP level rather than the IP level - so any large UDP packets would still end up breaking)
I've no idea what the underlying issue was, and at the client end the failure was entirely opaque: the remote simply stopped sending me packets. The only reason I was able to debug this at all was because I controlled the other end of the VPN as well, and even then I wouldn't have been able to do anything about it other than being in the fortuitous situation of someone able to do something about it seeing my post. How many people go through their lives dealing with things just being broken and having no idea why, and how do we fix that?
(Edit: thanks to this comment, it sounds like the underlying issue was a kernel bug that Fastly developed a fix for - under certain configurations, the kernel fails to associate the MTU update with the egress interface and so it continues sending overly large packets)
Speaking of S3 becoming strongly consistent, Swift was strongly consistent for objects in practice from the very beginning. All the "in practice" assumes a reasonably healthy cluster. It's very easy, really. When your client puts an object into a cluster and receives a 201, it means that a quorum of back-end nodes stored that object. Therefore, for you to get a stale version, you need to find a proxy that is willing to fetch you an old copy. That can only happen if the proxy has no access to any of the back-end nodes with the new object.
Somewhat unfortunately for the lovers of consistency, we made a decision that makes the observation of eventual consistency easier some 10 years ago. We allowed a half of an even replication factor to satisfy quorum. So, if you have a distributed cluster with factor of 4, a client can write an object into 2 nearest nodes, and receive a success. That opens a window for another client to read an old object from the other nodes.
Oh, well. Original Swift defaulted for odd replication factors, such as 3 and 5. They provided a bit of resistance to intercontinental scenarios, at the cost of the client knowing immediately if a partition is occurring. But a number of operators insisted that they preferred the observable eventual consistency. Remember that the replication factor is configurable, so there's no harm, right?
Alas, being flexible that way helps private clusters only. Because Swift generally hides the artitecture of the cluster from clients, they cannot know if they can rely on consistency of a random public cluster.
Either way, S3 does something that Swift cannot do here: the consistency of bucket listings. These things start lagging in Swift at a drop of a hat. If the container servers fail to reply in milliseconds, storage nodes push the job onto updaters and proceed. The delay in listigs is often observable in Swift, which is one reason why people doing POSIX overlays often have their own manifests.
I'm quite impressed by S3 doing this, given their scale especially. Curious, too. I wish I could hack on their system a little bit. But it's all proprietary, alas.
As was recently announced, the Linux kernel project has been accepted as a CNA as a CVE Numbering Authority (CNA) for vulnerabilities found in Linux.
This is a trend, of more open source projects taking over the haphazard assignments of CVEs against their project by becoming a CNA so that no other group can assign CVEs without their involvment. Here’s the curl project doing much the same thing for the same reasons.
The Linux Plumbers Conference is proud to announce that it’s website for 2024 is up and the CFP has been issued. We will be running a hybrid conference as usual, but the in-person venue will be Vienna, Austria from 18-20 September. Deadlines to submit are 4 April for Microconferences and 16 June for Refereed and Kernel Summit track presentations. Details for other tracks and accepted Microconferences will be posted later.
Vulkan Video AV1 decode has been released, and I had some partly working support on Intel ANV driver previously, but I let it lapse.
The branch is currently [1]. It builds, but is totally untested, I'll get some time next week to plug in my DG2 and see if I can persuade it to decode some frames.
Update: the current branch decodes one frame properly, reference frames need more work unfortunately.
In order to save mass-storage space and to reduce boot times, rcutorture runs out of a tiny initrd filesystem that consists only of a root directory and a statically linked init program based on nolibc. This init program binds itself to a randomly chosen CPU, spins for a short time, sleeps for a short time, and repeats, the point being to inject at least a little userspace execution for the benefit of nohz_full CPUs.
This works very well most of the time. But what if you want to use a full userspace when torturing RCU, perhaps because you want to test runtime changes to RCU's many sysfs parameters, run heavier userspace loads on nohz_full CPUs, or even to run BPF programs?
What you do is go back to the old way of building rcutorture's initrd.
Which raises the question as to what the new way might be.
What rcutorture does is to look at the tools/testing/selftests/rcutorture/initrd directory. If this directory does not already a file named init, the tools/testing/selftests/rcutorture/bin/mkinitrd.sh script builds the aforementioned statically linked init program.
Which means that you can put whatever initrd file tree you wish into that initrd directory, and as long as it contains a /init program, rcutorture will happily bundle that file tree into an initrd in each the resulting rcutorture kernel images.
And back in the old days, that is exactly what I did. I grabbed any convenient initrd and expanded it into my tools/testing/selftests/rcutorture/initrd directory. This still works, so you can do this too!
The Khronos Group announced VK_KHR_video_decode_av1 [1], this extension adds AV1 decoding to the Vulkan specification. There is a radv branch [2] and merge request [3]. I did some AV1 work on this in the past, but I need to take some time to see if it has made any progress since. I'll post an ANV update once I figure that out.
This extension is one of the ones I've been wanting for a long time, since having royalty-free codec is something I can actually care about and ship, as opposed to the painful ones. I started working on a MESA extension for this a year or so ago with Lynne from the ffmpeg project and we made great progress with it. We submitted that to Khronos and it has gone through the committee process and been refined and validated amongst the hardware vendors.
I'd like to say thanks to Charlie Turner and Igalia for taking over a lot of the porting to the Khronos extension and fixing up bugs that their CTS development brought up. This is a great feature of having open source drivers, it allows a lot quicker turn around time in bug fixes when devs can fix them themselves!
This article will discuss securing your phone after you’ve rooted it and installed your preferred os (it will not discuss how to root your phone or change the OS). Re-securing your phone requires the installation of a custom AVB key, which not all phones support, so I’ll only be discussing Google Pixel phones (which support this) and the LineageOS distribution (which is the one I use). The reason for wanting to do this is that by default LineageOS runs with the debug keys (i.e. known to everyone) with an unlocked bootloader, meaning OS updates and even binary changes to the system partition are easy to do. Since most android phones are fully locked, this isn’t a standard attack vector for malicious apps, but if someone is targetting you directly it may become one.
This article will cover how android verified boot (AVB) works, how to install your own custom AVB key and get a stock LineageOS distribution to use it and how to turn DM verity back on to make /system immutable.
A Brief Tour of Android Verified Boot (AVB)
We’ll actually be covering the 2.0 version of AVB, but that’s what most phones use today. The proprietary bootloader of a Pixel (the fastboot capable one you get to with adb reboot bootloader) uses a vbmeta partition to find the boot/recovery system and from there either enter recovery or boot the standard OS. vbmeta contains hashes for both this boot partition and the system partition. If your phone is unlocked the bootloader will simply boot the partitions vbmeta points to without any verification. If it is locked, the vbmeta partition must be signed by a key the phone knows. Pixel phones have two keyslots: a built in one which houses either the Google key or an OEM one and the custom slot, which is blank. In the unlocked mode, you can flash your own key into the custom slot using the fastboot flash avb_custom_key command.
The vbmeta partition also contains a boot flags region which tells the bootloader how to boot the OS. The two flags the OS knows about are in external/avb/libavb/avb_vbmeta_image.h:
/* Flags for the vbmeta image.
*
* AVB_VBMETA_IMAGE_FLAGS_HASHTREE_DISABLED: If this flag is set,
* hashtree image verification will be disabled.
*
* AVB_VBMETA_IMAGE_FLAGS_VERIFICATION_DISABLED: If this flag is set,
* verification will be disabled and descriptors will not be parsed.
*/
typedef enum {
AVB_VBMETA_IMAGE_FLAGS_HASHTREE_DISABLED = (1 << 0),
AVB_VBMETA_IMAGE_FLAGS_VERIFICATION_DISABLED = (1 << 1)
} AvbVBMetaImageFlags;
if the first flag is set then dm-verity is disabled and if the second one is set, the bootloader doesn’t pass the hash of the vbmeta partition on the kernel command line. In a standard LineageOS build, both these flags are set.
The reason for passing the vbmeta hash on the command line is so the android init process can load the vbmeta partition, hash it and verify against what the bootloader passed in, thus confirming there hasn’t been a time of check to time of use (TOCTOU) security breach. The init process cannot verify the signature for itself because the vbmeta signing public key isn’t built into the OS (which allows the OS to be signed after the images are build).
The description of the AVB_VBMETA_IMAGE_FLAGS_HASHTREE_DISABLED flag is slightly wrong. A standard android build always seems to calculate the dm-verity hash tree and insert it into the vbmeta partition (where it is verified by the vbmeta signature) it’s just that if this flag is set, the android init process won’t load the dm-verity hash tree and the system partition will thus be mutable.
Creating and Using your own custom Boot Key
Obviously android doesn’t use any standard tool form for its keys, so you have to create your own RSA 2048 (the literature implies it will work with 4096 as well but I haven’t tried it) AVB custom key using say openssl, then use avbtool (found in external/avb as a python script) to convert your RSA public key to a form that can be flashed in the phone:
This can then be flashed to the unlocked phone (in the bootloader fastboot) with
fastboot flash avb_custom_key pkmd.bin
And you’re all set up to boot a custom signed OS.
Signing your LineageOS
There is a wrinkle to this: to re-sign the OS, you need the target-files.zip intermediate build, not the ROM install file. Unfortunately, this is pretty big (38GB for lineage-19.1) and doesn’t seem to be available for download any more. If you can find it, you can re-sign the stock LineageOS, but if not you have to build it yourself. Instructions for both building and re-signing can be found here. You need to follow this but in addition you must add two extra flags to the sign_target_files_apks command:
Which will ensure the vbmeta partition is signed with the key you created above.
Optionally Enabling dm-verity
If you want to enable dm-verity, you have to change the vbmeta flags to 0 (enable both hashtree and vbmeta verification) before you execute the signing command above. These flags are stored in the META/misc_info.txt file which you can extract from target-files.zip with
unzip target-files.zip META/misc_info.txt
And once done you can vi this file to find the line
If you update the 3 to 0 this will unset the two disable flags and allow you to do a dm-verity verified boot. Then use zip to replace this updated file
zip -u target-files.zip META/misc_info.txt
And then proceed with signing the updated target-files.zip
Wrinkle for Android-12 (lineage-19.1) and above
For all these versions, this patch ensures that if the vbmeta was signed then the vbmeta hash must be verified, otherwise the system will crash in early init, so you have no choice and must alter the avb_vbmeta_args above to either --flags 1 or --flags 0 so the vbmeta hash is passed in to init. Since you have to alter the flags anyway, you might as well enable dm-verity (set to 0) at the same time.
Re-Lock the Bootloader
Once you have installed both your custom keys and your custom signed boot image, you are ready to re-lock the bootloader. Beware that some phones will erase your data partition when you do this (the Google advice says they shouldn’t, but not all manufacturers bother to follow it), so make sure you have a backup (or are playing with a newly rooted phone).
fastboot flashing lock
Check with a reboot (the phone should now display a yellow warning triangle saying it is booting a custom OS rather than the orange unsigned OS one). If everything goes according to plan you can enter the developer settings and click the “OEM Unlocking” settings to disabled and your phone can no longer be unlocked without your say so.
Conclusions and Caveats
Following the above instructions, you can updated your phone so it will verify images you signed with your AVB key, turn on dm-verity if you wish and generally make your phone much more secure. However, remember that you haven’t erased the original AVB key, so the phone can still be updated to an image signed with that key and, worse, the recovery partition of LineageOS is modified to allow rollback, so it will allow the flashing of any signed image without triggering an erase of the data partition. There are also a few more problems like, thanks to a bug in AOSP, the recovery version of fastboot will actually allow commands that are usually forbidden if the phone is locked.
Back in my blog post about Securing the Google SIP Stack, I did say I’d look at re-enabling SIP in Android-12, so with a view to doing that I tried building and booting LineageOS 19.1, but it crashed really early in the boot sequence (after the boot splash but before the boot animation started). It turns out that information on debugging the android early boot sequence is a bit scarce, so I thought I should write a post about how I did it just in case it helps someone else who’s struggling with a similar early boot problem.
How I usually Build and Boot Android
My builds are standard LineageOS with my patches to fix SIP and not much else. However, I do replace the debug keys with my signing keys and I also have an AVB key installed in the phone’s third party keyslot with which I sign the vbmeta for boot. This actually means that my phone is effectively locked but with a user supplied key (Yellow as google puts it).
My phone is now a pixel 3 (I had to say goodbye to the old Nexus One thanks to the US 3G turn off) and I do have a slightly broken Pixel 3 I play with for experimental patches, which is where I was trying to install Android-12.
Signing Seems to be the Problem
Just to verify my phone could actually boot a stock LineageOS (it could) I had to unlock it and this lead to the discovery that once unlocked, it would also boot my custom rom as well, so whatever was failing in early boot seemed to be connected with the device being locked.
I also discovered an interesting bug in the recovery rom fastboot: If you’re booting locked with your own keys, it will still let you perform all the usually forbidden fastboot commands (the one I was using was set_active). It turns out to be because of a bug in AOSP which treats yellow devices as unlocked in fastboot. Somewhat handy for debugging, but not so hot for security …
And so to Debugging Early Boot
The big problem with Android is there’s no way to get the console messages for early boot. Even if you enable adb early, it doesn’t get started until quite far in to the boot animation (which was way after the crash I was tripping over). However, android does have a pstore (previously ramoops) driver that can give you access to the previously crashed boot’s kernel messages (early init, fortunately, mostly logs to the kernel message log).
Forcing init to crash on failure
Ordinarily an init failure prints a message and reboots (to the bootloader), which doesn’t excite pstore into saving the kernel message log. fortunately there is a boot option (androidboot.init_fatal_panic) which can be set in the boot options (or kernel command line for a pixel-3 which can only boot the 4.9 kernel). If you build your own android, it’s fairly easy to add things to the android commandline (which is in boot.img) because all you need to do is extract BOOT/cmdline from the intermediate zip file you sign add any boot options you need and place it back in the zip file (before you sign it).
Unfortunately, this expedient didn’t work (no console logs appear in pstore). I did check that init was correctly panic’ing on failure by inducing an init failure in recovery mode and observing the panic (recovery mode allows you to run adb). But this induced panic also didn’t show up in pstore, meaning there’s actually some problem with pstore and early panics.
Security is the problem (as usual)
The actual problem turned out to be security (as usual): The pixel-3 does encrypted boot panic logs. The way this seems to work (at least in my reading of the google additional pstore patches) is that the bootloader itself encrypts the pstore ram area with a key on the /data partition, which means it only becomes visible after the device is unlocked. Unfortunately, if you trigger a panic before the device is unlocked (by echoing ‘c’ to /proc/sysrq-trigger) the panic message is lost, so pstore itself is useless for debugging early boot. There seems to be some communication of the keys by the vendor proprietary ramoops binary making it very difficult to figure out how it’s being done.
Why the early panic message is lost is a bit mysterious, but unfortunately pstore on the pixel-3 has several proprietary components around the encrypted message handling that make it hard to debug. I suspect if you don’t set up the pstore encryption keys, the bootloader erases the pstore ram area instead of encrypting it, but I can’t prove that.
Although it might be possible to fix the pstore drivers to preserve the ramoops from before device unlock, the participation of the proprietary bootloader in preserving the memory doesn’t make that look like a promising avenue to explore.
Anatomy of the Pixel-3 Boot Sequence
The Pixel-3 device boots through recovery. What this means is that the initial ramdisk (from boot.img) init is what boots both the recovery and normal boot paths. The only difference is that for recovery (and fastboot), the device stays in the ramdisk and for normal boot it mounts the /system partition and pivots to it. What makes this happen or not is the boot flag androidboot.force_normal_boot=1 which is added by the bootloader. Pretty much all the binary content and init rc files in the ramdisk are for recovery and its allied menus.
Since the boot paths are pretty radically different, because the normal boot first pivots to a first stage before going on to a second, but in the manner of containers, it might be possible to boot recovery first, start a dmesg logger and then re-exec init through the normal path
Forcing Re-Exec
The idea is to signal init to re-exec itself for the normal path. Of course, there have to be a few changes to do this: An item has to be added to the recovery menu to signal init and init itself has to be modified to do the re-exec on the signal (note you can’t just kick off an init with a new command line because init must be pid 1 for booting). Once this is done, there are problems with selinux (it won’t actually allow init to re-exec) and some mount moves. The selinux problem is fixable by switching it from enforcing to permissive (boot option androidboot.selinux=permissive) and the mount moves (which are forbidden if you’re running binaries from the mount points being moved) can instead become bind mounts. The whole patch becomes 31 insertions across 7 files in android_system_core.
The signal I chose was SIGUSR1, which isn’t usually used by anything in the bootloader and the addition of a menu item to recovery to send this signal to init was also another trivial patch. So finally we have a system from which I can start adb to trace the kernel log (adb shell dmesg -w) and then signal to init to re-exec. Surprisingly this worked and produced as the last message fragment:
[ 190.966881] init: [libfs_mgr]Created logical partition system_a on device /dev/block/dm-0
[ 190.967697] init: [libfs_mgr]Created logical partition vendor_a on device /dev/block/dm-1
[ 190.968367] init: [libfs_mgr]Created logical partition product_a on device /dev/block/dm-2
[ 190.969024] init: [libfs_mgr]Created logical partition system_ext_a on device /dev/block/dm-3
[ 190.969067] init: DSU not detected, proceeding with normal boot
[ 190.982957] init: [libfs_avb]Invalid hash size:
[ 190.982967] init: [libfs_avb]Failed to verify vbmeta digest
[ 190.982972] init: [libfs_avb]vbmeta digest error isn't allowed
[ 190.982980] init: Failed to open AvbHandle: No such file or directory
[ 190.982987] init: Failed to setup verity for '/system': No such file or directory
[ 190.982993] init: Failed to mount /system: No such file or directory
[ 190.983030] init: Failed to mount required partitions early …
[ 190.983483] init: InitFatalReboot: signal 6
[ 190.984849] init: #00 pc 0000000000123b38 /system/bin/init
[ 190.984857] init: #01 pc 00000000000bc9a8 /system/bin/init
[ 190.984864] init: #02 pc 000000000001595c /system/lib64/libbase.so
[ 190.984869] init: #03 pc 0000000000014f8c /system/lib64/libbase.so
[ 190.984874] init: #04 pc 00000000000e6984 /system/bin/init
[ 190.984878] init: #05 pc 00000000000aa144 /system/bin/init
[ 190.984883] init: #06 pc 00000000000487dc /system/lib64/libc.so
[ 190.984889] init: Reboot ending, jumping to kernel
Which indicates exactly where the problem is.
Fixing the problem
Once the messages are identified, the problem turns out to be in system/core ec10d3cf6 “libfs_avb: verifying vbmeta digest early”, which is inherited from AOSP and which even says in in it’s commit message “the device will not boot if: 1. The image is signed with FLAGS_VERIFICATION_DISABLED is set 2. The device state is locked” which is basically my boot state, so thanks for that one google. Reverting this commit can be done cleanly and now the signed image boots without a problem.
I note that I could also simply add hashtree verification to my boot, but LineageOS is based on the eng target, which has FLAGS_VERIFICATION_DISABLED built into the main build Makefile. It might be possible to change it, but not easily I’m guessing … although I might try fixing it this way at some point, since it would make my phones much more secure.
Conclusion
Debugging android early boot is still a terribly hard problem. Probably someone with more patience for disassembling proprietary binaries could take apart pixel-3 vendor ramoops and figure out if it’s possible to get a pstore oops log out of early boot (which would be the easiest way to debug problems). But failing that the simple hack to re-exec init worked enough to show me where the problem was (of course, if init had continued longer it would likely have run into other issues caused by the way I hacked it).
Libraries are collections of code that are intended to be usable by multiple consumers (if you're interested in the etymology, watch this video). In the old days we had what we now refer to as "static" libraries, collections of code that existed on disk but which would be copied into newly compiled binaries. We've moved beyond that, thankfully, and now make use of what we call "dynamic" or "shared" libraries - instead of the code being copied into the binary, a reference to the library function is incorporated, and at runtime the code is mapped from the on-disk copy of the shared object[1]. This allows libraries to be upgraded without needing to modify the binaries using them, and if multiple applications are using the same library at once it only requires that one copy of the code be kept in RAM.
But for this to work, two things are necessary: when we build a binary, there has to be a way to reference the relevant library functions in the binary; and when we run a binary, the library code needs to be mapped into the process.
(I'm going to somewhat simplify the explanations from here on - things like symbol versioning make this a bit more complicated but aren't strictly relevant to what I was working on here)
For the first of these, the goal is to replace a call to a function (eg, printf()) with a reference to the actual implementation. This is the job of the linker rather than the compiler (eg, if you use the -c argument to tell gcc to simply compile to an object rather than linking an executable, it's not going to care about whether or not every function called in your code actually exists or not - that'll be figured out when you link all the objects together), and the linker needs to know which symbols (which aren't just functions - libraries can export variables or structures and so on) are available in which libraries. You give the linker a list of libraries, it extracts the symbols available, and resolves the references in your code with references to the library.
But how is that information extracted? Each ELF object has a fixed-size header that contains references to various things, including a reference to a list of "section headers". Each section has a name and a type, but the ones we're interested in are .dynstr and .dynsym. .dynstr contains a list of strings, representing the name of each exported symbol. .dynsym is where things get more interesting - it's a list of structs that contain information about each symbol. This includes a bunch of fairly complicated stuff that you need to care about if you're actually writing a linker, but the relevant entries for this discussion are an index into .dynstr (which means the .dynsym entry isn't sufficient to know the name of a symbol, you need to extract that from .dynstr), along with the location of that symbol within the library. The linker can parse this information and obtain a list of symbol names and addresses, and can now replace the call to printf() with a reference to libc instead.
(Note that it's not possible to simply encode this as "Call this address in this library" - if the library is rebuilt or is a different version, the function could move to a different location)
Experimentally, .dynstr and .dynsym appear to be sufficient for linking a dynamic library at build time - there are other sections related to dynamic linking, but you can link against a library that's missing them. Runtime is where things get more complicated.
When you run a binary that makes use of dynamic libraries, the code from those libraries needs to be mapped into the resulting process. This is the job of the runtime dynamic linker, or RTLD[2]. The RTLD needs to open every library the process requires, map the relevant code into the process's address space, and then rewrite the references in the binary into calls to the library code. This requires more information than is present in .dynstr and .dynsym - at the very least, it needs to know the list of required libraries.
There's a separate section called .dynamic that contains another list of structures, and it's the data here that's used for this purpose. For example, .dynamic contains a bunch of entries of type DT_NEEDED - this is the list of libraries that an executable requires. There's also a bunch of other stuff that's required to actually make all of this work, but the only thing I'm going to touch on is DT_HASH. Doing all this re-linking at runtime involves resolving the locations of a large number of symbols, and if the only way you can do that is by reading a list from .dynsym and then looking up every name in .dynstr that's going to take some time. The DT_HASH entry points to a hash table - the RTLD hashes the symbol name it's trying to resolve, looks it up in that hash table, and gets the symbol entry directly (it still needs to resolve that against .dynstr to make sure it hasn't hit a hash collision - if it has it needs to look up the next hash entry, but this is still generally faster than walking the entire .dynsym list to find the relevant symbol). There's also DT_GNU_HASH which fulfills the same purpose as DT_HASH but uses a more complicated algorithm that performs even better. .dynamic also contains entries pointing at .dynstr and .dynsym, which seems redundant but will become relevant shortly.
So, .dynsym and .dynstr are required at build time, and both are required along with .dynamic at runtime. This seems simple enough, but obviously there's a twist and I'm sorry it's taken so long to get to this point.
I bought a Synology NAS for home backup purposes (my previous solution was a single external USB drive plugged into a small server, which had uncomfortable single point of failure properties). Obviously I decided to poke around at it, and I found something odd - all the libraries Synology ships were entirely lacking any ELF section headers. This meant no .dynstr, .dynsym or .dynamic sections, so how was any of this working? nm asserted that the libraries exported no symbols, and readelf agreed. If I wrote a small app that called a function in one of the libraries and built it, gcc complained that the function was undefined. But executables on the device were clearly resolving the symbols at runtime, and if I loaded them into ghidra the exported functions were visible. If I dlopen()ed them, dlsym() couldn't resolve the symbols - but if I hardcoded the offset into my code, I could call them directly.
Things finally made sense when I discovered that if I passed the --use-dynamic argument to readelf, I did get a list of exported symbols. It turns out that ELF is weirder than I realised. As well as the aforementioned section headers, ELF objects also include a set of program headers. One of the program header types is PT_DYNAMIC. This typically points to the same data that's present in the .dynamic section. Remember when I mentioned that .dynamic contained references to .dynsym and .dynstr? This means that simply pointing at .dynamic is sufficient, there's no need to have separate entries for them.
The same information can be reached from two different locations. The information in the section headers is used at build time, and the information in the program headers at run time[3]. I do not have an explanation for this. But if the information is present in two places, it seems obvious that it should be able to reconstruct the missing section headers in my weird libraries? So that's what this does. It extracts information from the DYNAMIC entry in the program headers and creates equivalent section headers.
There's one thing that makes this more difficult than it might seem. The section header for .dynsym has to contain the number of symbols present in the section. And that information doesn't directly exist in DYNAMIC - to figure out how many symbols exist, you're expected to walk the hash tables and keep track of the largest number you've seen. Since every symbol has to be referenced in the hash table, once you've hit every entry the largest number is the number of exported symbols. This seemed annoying to implement, so instead I cheated, added code to simply pass in the number of symbols on the command line, and then just parsed the output of readelf against the original binaries to extract that information and pass it to my tool.
Somehow, this worked. I now have a bunch of library files that I can link into my own binaries to make it easier to figure out how various things on the Synology work. Now, could someone explain (a) why this information is present in two locations, and (b) why the build-time linker and run-time linker disagree on the canonical source of truth?
[1] "Shared object" is the source of the .so filename extension used in various Unix-style operating systems [2] You'll note that "RTLD" is not an acryonym for "runtime dynamic linker", because reasons [3] For environments using the GNU RTLD, at least - I have no idea whether this is the case in all ELF environments
A while ago I mentioned I use Android-10 with the built in SIP stack and that the Google stack was pretty buggy and I had to fix it simply to get it to function without disconnecting all the time. Since then I’ve upported my fixes to Android-11 (the jejb-11 branch in the repositories) by using LineageOS-19.1. However, another major deficiency in the Google SIP stack is its complete lack of security: both the SIP signalling and the media streams are all unencrypted meaning they can be intercepted and tapped by pretty much anyone in the network path running tcpdump. Why this is so, particularly for a company that keeps touting its security credentials is anyone’s guess. I personally suspect they added SIP in Android-4 with a view to basing Google Voice on it, decided later that proprietary VoIP protocols was the way to go but got stuck with people actually using the SIP stack for other calling services so they couldn’t rip it out and instead simply neglected it hoping it would die quietly due to lack of features and updates.
This blog post is a guide to how I took the fully unsecured Google SIP stack and added security to it. It also gives a brief overview of some of the security protocols you need to understand to get secure VoIP working.
What is SIP
What I’m calling SIP (but really a VoIP system using SIP) is a protocol consisting of several pieces. SIP (Session Initiation Protocol), RFC 3261, is really only one piece: it is the “signalling” layer meaning that call initiation, response and parameters are all communicated this way. However, simple SIP isn’t enough for a complete VoIP stack; once a call moves to in progress, there must be an agreement on where the media streams are and how they’re encoded. This piece is called a SDP (Session Description Protocol) agreement and is usually negotiated in the body of the SIP INVITE and response messages and finally once agreement is reached, the actual media stream for call audio goes over a different protocol called RTP (Real-time Transport Protocol).
How Google did SIP
The trick to adding protocols fast is to take them from someone else (if you’re open source, this is encouraged) so google actually chose the NIST-SIP java stack (which later became the JAIN-SIP stack) as the basis for SIP in android. However, that only covered signalling and they had to plumb it in to the android Phone model. One essential glue piece is frameworks/opt/net/voip which supplies the SDP negotiating layer and interfaces the network codec to the phone audio. This isn’t quite enough because the telephony service and the Dialer also need to be involved to do the account setup and call routing. It always interested me that SIP was essentially special cased inside these services and apps instead of being a plug in, but that’s due to the fact that some of the classes that need extending to add phone protocols are internal only; presumably so only manufacturers can add phone features.
Securing SIP
This is pretty easy following the time honoured path of sending messages over TLS instead of in the clear simply by using a TLS wrappering technique of secure sockets and, indeed, this is how RFC 3261 says to do it. However, even this minor re-engineering proved unnecessary because the nist-sip stack was already TLS capable, it simply wasn’t allowed to be activated that way by the configuration options Google presented. A simple 10 line patch in a couple of repositories (external/nist_sip, packages/services/Telephony and frameworks/opt/net/voip) fixed this and the SIP stack messaging was secured leaving only the voice stream insecure.
SDP
As I said above, the google frameworks/opt/net/voip does all the SDP negotiation. This isn’t actually part of SIP. The SDP negotiation is conducted over SIP messages (which means it’s secured thanks to the above) but how this should be done isn’t part of the SIP RFC. Instead SDP has its own RFC 4566 which is what the class follows (mainly for codec and port negotiation). You’d think that if it’s already secured by SIP, there’s no additional problem, but, unfortunately, using SRTP as the audio stream requires the exchange of additional security parameters which added to SDP by RFC 4568. To incorporate this into the Google SIP stack, it has to be integrated into the voip class. The essential additions in this RFC are a separate media description protocol (RTP/SAVP) for the secure stream and the addition of a set of tagged a=crypto: lines for key negotiation.
As will be a common theme: not all of RFC 4568 has to be implemented to get a secure RTP stream. It goes into great detail about key lifetime and master key indexes, neither of which are used by the asterisk SIP stack (which is the one my phone communicates with) so they’re not implemented. Briefly, it is best practice in TLS to rekey the transport periodically, so part of key negotiation should be key lifetime (actually, this isn’t as important to SRTP as it is to TLS, see below, which is why asterisk ignores it) and the people writing the spec thought it would be great to have a set of keys to choose from instead of just a single one (The Master Key Identifier) but realistically that simply adds a load of complexity for not much security benefit and, again, is ignored by asterisk which uses a single key.
In the end, it was a case of adding a new class for parsing the a=crypto: lines of SDP and doing a loop in the audio protocol for RTP/SAVP if TLS were set as the transport. This ended up being a ~400 line patch.
Secure RTP
RTP itself is governed by RFC 3550 which actually contains two separate stream descriptions: the actual media over RTP and a control protocol over RTCP. RTCP is mostly used for multi-party and video calls (where you want reports on reception quality to up/downshift the video resolution) and really serves no purpose for audio, so it isn’t implemented in the Google SIP stack (and isn’t really used by asterisk for audio only either).
When it comes to securing RTP (and RTCP) you’d think the time honoured mechanism (using secure sockets) would have applied although, since RTP is transmitted over UDP, one would have to use DTLS instead of TLS. Apparently the IETF did consider this, but elected to define a new protocol instead (or actually two: SRTP and SRTCP) in RFC 3711. One of the problems with this new protocol is that it also defines a new ciphersuite (AES_CM_…) which isn’t found in any of the standard SSL implementations. Although the AES_CM ciphers are very similar in operation to the AES_GCM ciphers of TLS (Indeed AES_GCM was adopted for SRTP in a later RFC 7714) they were never incorporated into the TLS ciphersuite definition.
So now there are two problems: adding code for the new protocol and performing the new encyrption/decryption scheme. Fortunately, there already exists a library (libsrtp) that can do this and even more fortunately it’s shipped in android (external/libsrtp2) although it looks to be one of those throwaway additions where the library hasn’t really been updated since it was added (for cuttlefish gcastv2) in 2019 and so is still at a pre 2.3.0 version (I did check and there doesn’t look to be any essential bug fixes missing vs upstream, so it seems usable as is).
One of the really great things about libsrtp is that it has srtp_protect and srtp_unprotect functions which transform SRTP to RTP and vice versa, so it’s easily possible to layer this library directly into an existing RTP implementation. When doing this you have to remember that the encryption also includes authentication, so the size of the packet expands which is why the initial allocation size of the buffers has to be increased. One of the not so great things is that it implements all its own crypto primitives including AES and SHA1 (which most cryptographers think is always a bad idea) but on the plus side, it’s the same library asterisk uses so how much of a real problem could this be …
Following the simple layering approach, I constructed a patch to do the RTP<->SRTP transform in the JNI code if a key is passed in, so now everything just works and setting asterisk to SRTP only confirms the phone is able to send and receive encrypted audio streams. This ends up being a ~140 line patch.
So where does DTLS come in?
Anyone spending any time at all looking at protocols which use RTP, like webRTC, sees RTP and DTLS always mentioned in the same breath. Even asterisk has support for DTLS, so why is this? The answer is that if you use RTP outside the SIP framework, you still need a way of agreeing on the keys using SDP. That key agreement must be protected (and can’t go over RTCP because that would cause a chicken and egg problem) so implementations like webRTC use DTLS to exchange the initial SDP offer and answer negotiation. This is actually referred to as DTLS-SRTP even though it’s an initial DTLS handshake followed by SRTP (with no further DTLS in sight). However, this DTLS handshake is completely unnecessary for SIP, since the SDP handshake can be done over TLS protected SIP messaging instead (although I’ve yet to find anyone who can convincingly explain why this initial handshake has to go over DTLS and not TLS like SIP … I suspect it has something to do with wanting the protocol to be all UDP and go over the same initial port).
Conclusion
This whole exercise ended up producing less than 1000 lines in patches and taking a couple of days over Christmas to complete. That’s actually much simpler and way less time than I expected (given the complexity in the RFCs involved), which is why I didn’t look at doing this until now. I suppose the next thing I need to look at is reinserting the SIP stack into Android-12, but I’ll save that for when Android-11 falls out of support.
Vulkan 1.3.274 moves the Vulkan encode work out of BETA and moves h264 and h265 into KHR extensions. radv support for the Vulkan video encode extensions has been in progress for a while.
The latest branch is at [1]. This branch has been updated for the new final headers.
Updated: It passes all of h265 CTS now, but it is failing one h264 test.
Earlier this year, after Github accidentally committed their private RSA SSH host key to a public repository, I wrote about how better support for SSH host certificates would allow this sort of situation to be handled in a user-transparent way without any negative impact on security. I was hoping that someone would read this and be inspired to fix the problem but sadly that didn't happen so I've actually written some code myself.
The core part of this is straightforward - if a server presents you with a certificate associated with a host key, then make the trust in that host be whoever signed the certificate rather than just trusting the host key. This means that if someone needs to replace the host key for any reason (such as, for example, them having published the private half), you can replace the host key with a new key and a new certificate, and as long as the new certificate is signed by the same key that the previous certificate was, you'll trust the new key and key rotation can be carried out without any user errors. Hurrah!
So obviously I wrote that bit and then thought about the failure modes and it turns out there's an obvious one - if an attacker obtained both the private key and the certificate, what stops them from continuing to use it? The certificate isn't a secret, so we basically have to assume that anyone who possesses the private key has access to it. We may have silently transitioned to a new host key on the legitimate servers, but a hostile actor able to MITM a user can keep on presenting the old key and the old certificate until it expires.
There's two ways to deal with this - either have short-lived certificates (ie, issue a new certificate every 24 hours or so even if you haven't changed the key, and specify that the certificate is invalid after those 24 hours), or have a mechanism to revoke the certificates. The former is viable if you have a very well-engineered certificate issuing operation, but still leaves a window for an attacker to make use of the certificate before it expires. The latter is something SSH has support for, but the spec doesn't define any mechanism for distributing revocation data.
So, I've implemented a new SSH protocol extension that allows a host to send a key revocation list to a client. The idea is that the client authenticates to the server, receives a key revocation list, and will no longer trust any certificates that are contained within that list. This seems simple enough, but a naive implementation opens the client to various DoS attacks. For instance, if you simply revoke any key contained within the received KRL, a hostile server could revoke any certificates that were otherwise trusted by the client. The easy way around this is for the client to ensure that any revoked keys are associated with the same CA that signed the host certificate - that way a compromised host can only revoke certificates associated with that CA, and can't interfere with anyone else.
Unfortunately that still means that a single compromised host can still trigger revocation of certificates inside that trust domain (ie, a compromised host a.test.com could push a KRL that invalidated the certificate for b.test.com), because there's no way in the KRL format to indicate that a given revocation is associated with a specific hostname. This means we need a mechanism to verify that the KRL update is legitimate, and the easiest way to handle that is to sign it. The KRL format specifies an in-band signature but this was deprecated earlier this year - instead KRLs are supposed to be signed with the sshsig format. But we control both the server and the client, which means it's easy enough to send a detached signature as part of the extension data.
Putting this all together: you ssh to a server you've never contacted before, and it presents you with a host certificate. Instead of the host key being added to known_hosts, the CA key associated with the certificate is added. From now on, if you ssh to that host and it presents a certificate signed by that CA, it'll be trusted. Optionally, the host can also send you a KRL and a signature. If the signature is generated by the CA key that you already trust, any certificates in that KRL associated with that CA key will be incorporated into local storage. The expected flow if a key is compromised is that the owner of the host generates a new keypair, obtains a new certificate for the new key, and adds the old certificate to a KRL that is signed with the CA key. The next time the user connects to that host, they receive the new key and new certificate, trust it because it's signed by the same CA key, and also receive a KRL signed with the same CA that revokes trust in the old certificate.
Obviously this breaks down if a user is MITMed with a compromised key and certificate immediately after the host is compromised - they'll see a legitimate certificate and won't receive any revocation list, so will trust the host. But this is the same failure mode that would occur in the absence of keys, where the attacker simply presents the compromised key to the client before trust in the new key has been created. This seems no worse than the status quo, but means that most users will seamlessly transition to a new key and revoke trust in the old key with no effort on their part.
The work in progress tree for this is here - at the point of writing I've merely implemented this and made sure it builds, not verified that it actually works or anything. Cleanup should happen over the next few days, and I'll propose this to upstream if it doesn't look like there's any showstopper design issues.
Even if you’re a developer with legal leanings like me, you probably haven’t given much thought to the warranty disclaimer and the liability disclaimer that appears in almost every Open Source licence (see sections 14 and 15 of GPLv3). This post is designed to help you understand what they are, why they’re there and why we might need stronger defences in future thanks to a changing legal landscape.
History: Why no Warranty or Liability
It seems obvious that when considered in terms of what downstream gets from Open Source that an open ended obligation on behalf of upstream to fix your problems isn’t one of them because it wouldn’t be sustainable. Effectively the no warranty clause is notice that since you’re getting the code for free it comes with absolutely no obligations on developers: if it breaks, you get to fix it. This is why no warranty clauses have been present since the history of Open Source (and Free Software: GPLv1 included this). There’s also a historical commercial reason for this as well. Before the explosion of Open Source business models in the last decade, the Free Software Foundation (FSF) considered paid support for otherwise unsupported no warranty Open Source software to be the standard business model for making money on Open Source. Based on this, Cygnus Support (later Cygnus Solutions – Earliest web archive capture 1997) was started in 1989 with a business model of providing paid support and bespoke development for the compiler and toolchain.
Before 2000 most public opinion (when it thought about Open Source at all) was happy with this, because Open Source was seen by and large as the uncommercialized offerings of random groups of hackers. Even the largest Open Source project, the Linux kernel, was seen as the scrappy volunteer upstart challenging both Microsoft and the proprietary UNIXs for control of the Data Centre. On the back of this, distributions (Red Hat, SUSE, etc.) arose to commericallize support offerings around Linux to further its competition with UNIX and Windows and push it to win the war for the Data Centre (and later the Cloud).
The Rise of The Foundations: Public Perception Changes
The heyday explosion of volunteer Open Source happened in the first decade of the new Millennium. But volunteer Open Source also became a victim of this success: the more it penetrated industry, the greater control of the end product industry wanted. And, whenever there’s a Business Need, something always arises to fulfill it: the Foundation Model for exerting influence in exchange for cash. The model is fairly simple: interested parties form a foundation (or more likely go to a Foundation forming entity like the Linux Foundation). They get seats on the governing board, usually in proportion to their annual expenditure on the foundation and the foundation sets up a notionally independent Technical Oversight Body staffed by developers which is still somewhat beholden to the board and its financial interests. The net result is rising commercial franchise in Open Source.
The point of the above isn’t to say whether this commercial influence is good or bad, it’s to say that the rise of the Foundations have changed the public perception of Open Source. No longer is Open Source seen as the home of scrappy volunteers battling for technological innovation against entrenched commercial interests, now Open Source is seen as one more development tool of the tech industry. This change in attitude is pretty profound because now when a problem is found in Open Source, the public has no real hesitation in assuming the tech industry in general should be responsible; the perception that the no warranty clause protects innocent individual developers is supplanted by the perception that it’s simply one more tool big tech deploys to evade liability for the problems it creates. Some Open Source developers have inadvertently supported this notion by publicly demanding to be paid for working on their projects, often in the name of sustainability. Again, none of this is necessarily wrong but it furthers the public perception that Open Source developers are participating in a commercial not a volunteer enterprise.
Liability via Fiduciary Duty: The Bitcoin Case
An ongoing case in the UK courts (BL-2021-000313) between Tulip Trading and various bitcoin developers centers around the disputed ownership of about US$4bn in bitcoin. Essentially Tulip contends that it lost access to the bitcoins due to a computer hack but says that the bitcoin developers have a fiduciary duty to it to alter the blockchain code to recover its lost bitcoins. The unusual feature of this case is that Tulip sued the developers of the bitcoin code not the operators of the bitcoin network. (it’s rather like the Bank losing your money and then you trying to sue the Mint for recovery). The reason for this is that all the operators (the miners) use the same code base for the same blockchain and thus could rightly claim that it’s technologically impossible for them to recover the lost bitcoin, because that would necessitate a change to the fundamental blockchain code which only the developers control. The suit was initially lost by Tulip on the grounds of the no liability disclaimer, but reinstated by the UK appeal court which showed considerable interest in the idea that developers could pick up fiduciary liability in some cases, even though the suit may eventually get dismissed on the grounds that Tulip can’t prove it ever owned the US$4bn in bitcoins in the first place.
Why does all this matter? Well, even if this case resolves successfully, thanks to the appeal court ruling, the door is still open to others with less shady claims that they’ve suffered an injury due to some coding issue that gives developers fiduciary liability to them. The no warranty disclaimer is already judged not to be sufficient to prevent this, so the cracks are starting to appear in it as a defence against all liability claims.
The EU Cyber Resilience Act: Legally Piercing No Warranty Clauses
The EU Cyber Resilience Act (CRA) at its heart provides a fiduciary duty of care on all “digital components” incorporated into products or software offered on the EU market to adhere to prescribed cybersecurity requirements and an obligation to provide duty of care for these requirements over the whole lifecycle of such products or software. Essentially this is developer liability, notwithstanding any no warranty clauses, writ large. To be fair, there is currently a carve out for “noncommercial” Open Source but, as I pointed out above, most Open Source today is commercial and wouldn’t actually benefit from this. I’m not proposing to give a detailed analysis (many people have already done this and your favourite search engine will turn up dozens without even trying) I just want to note that this is a legislative act designed to pierce the no warranty clauses Open Source has relied on for so long.
EU CRA Politics: Why is this Popular?
Politicians don’t set out to effectively override licensing terms and contract law unless there’s a significant popularity upside and, if you actually canvas the general public, there is: People are tired of endless cybersecurity breaches compromising their private information, or even their bank accounts, and want someone to be held responsible. Making corporations pay for breaches that damage individuals is enormously popular (and not just in the EU). After all big Tech profits enormously from this, so big Tech should pay for the clean up when things go wrong.
Unfortunately, self serving arguments that this will place undue burdens on Foundations funded by starving corporations rather undermine the same arguments on behalf of individual developers. To the public at large such arguments merely serve to reinforce the idea that big Tech has been getting away with too much for too long. Trying to separate individual developer Open Source from corporate Open Source is too subtle a concept to introduce now, particularly when we, and the general public, have bought into the idea that they’re the same thing for so long.
So what should we do about this?
It’s clear that even if a massive (and expensive) lobbying effort succeeds in blunting the effect of the CRA on Open Source this time around, there will always be a next time because of the public desire for accountability for and their safety guarantees in cybersecurity practices. It is also clear that individual developer Open Source has to make common cause with commercial Open Source to solve this issue. Even though individuals hate being seen as synonymous with corporations, one of the true distinctions between Open Source and Free Software has always been the ability to make common cause over smaller goals rather than bigger philosophies and aspirations; so this is definitely a goal we can make a common cause over. This common cause means the eventual solution must apply to individual and commercial Open Source equally. And, since we’ve already lost the perception war, it will have to be something more legally based.
Indemnification: the Legal solution to Developer Liability
Indemnification means one party, in particular circumstances, agreeing to be on the hook for the legal responsibilities of another party. This is actually a well known way not of avoiding liability but transferring it to where it belongs. As such, it’s easily sellable in the court of public opinion: we’re not looking to avoid liability, merely trying to make sure it lands on those who are making all the money from the code.
The best mechanism for transmitting this is obviously the Licence and, ironically, a licence already exists with developer indemnity clauses: Apache-2 (clause 9). Unfortunately, the Apache-2 clause only attaches to an entity offering support for a fee, which doesn’t quite cover the intention of the CRA, which is for anyone offering a product in the EU market (whether free or for sale) should be responsible for its cybersecurity lifecycle, whether they offer support or not. However, it does provide a roadmap for what such a clause would look like:
If you choose to offer this work in whole or part as a component or product in a jurisdiction requiring lifecycle duty of care you agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your actions in such a jurisdiction.
Probably the wording would need some tweaking by an actual lawyer, but you get the idea.
Applying Indemnity to existing Licences
Obviously for a new project, the above clause can simply be added to the licence but for any existing project, since the clause is compatible with the standard no-warranty statements, it can be added after the fact without interfering with the existing operation of the licence or needing buy in from current copyright holders (there is an argument that this would represent an additional restriction within the meaning of GPL, but I addressed that here). This makes it very easy to add by anyone offering, for instance, a download over Github or Gitlab that could be incorporated by someone into a product in the EU.
Conclusion
Thanks to public perception, the issue of developer liability isn’t going to go away and lobbying will not forestall the issue forever, so a robust indemnity defence needs to be incorporated into Open Source licences so that Liability is seen to be accepted where it can best be served (by the people or corporation utilizing the code).
Problem: you run a Pleroma instance, and you want to restrict the composite timelines to logged-in users only, but without going to the full "public: false". This is a common ask, and the option restrict_unauthenticated is documented, but the syntax is far from obvious!
Problem: you create and VM like you always did, but RHEL 9 bombs with:
Fatal glibc error: CPU does not support x86-64-v2
Solution: as Dan Berrange explains in bug #2060839, a traditional default CPU model qemu64 is no longer sufficient. Unfortunately, there's no "qemu64-v2". Instead, you must select one of the real CPUs.
There's a decent number of laptops with fingerprint readers that are supported by Linux, and Gnome has some nice integration to make use of that for authentication purposes. But if you log in with a fingerprint, the moment you start any app that wants to access stored passwords you'll get a prompt asking you to type in your password, which feels like it somewhat defeats the point. Mac users don't have this problem - authenticate with TouchID and all your passwords are available after login. Why the difference?
Fingerprint detection can be done in two primary ways. The first is that a fingerprint reader is effectively just a scanner - it passes a graphical representation of the fingerprint back to the OS and the OS decides whether or not it matches an enrolled finger. The second is for the fingerprint reader to make that determination itself, either storing a set of trusted fingerprints in its own storage or supporting being passed a set of encrypted images to compare against. Fprint supports both of these, but note that in both cases all that we get at the end of the day is a statement of "The fingerprint matched" or "The fingerprint didn't match" - we can't associate anything else with that.
Apple's solution involves wiring the fingerprint reader to a secure enclave, an independently running security chip that can store encrypted secrets or keys and only release them under pre-defined circumstances. Rather than the fingerprint reader providing information directly to the OS, it provides it to the secure enclave. If the fingerprint matches, the secure enclave can then provide some otherwise secret material to the OS. Critically, if the fingerprint doesn't match, the enclave will never release this material.
And that's the difference. When you perform TouchID authentication, the secure enclave can decide to release a secret that can be used to decrypt your keyring. We can't easily do this under Linux because we don't have an interface to store those secrets. The secret material can't just be stored on disk - that would allow anyone who had access to the disk to use that material to decrypt the keyring and get access to the passwords, defeating the object. We can't use the TPM because there's no secure communications channel between the fingerprint reader and the TPM, so we can't configure the TPM to release secrets only if an associated fingerprint is provided.
So the simple answer is that fingerprint unlock doesn't unlock the keyring because there's currently no secure way to do that. It's not intransigence on the part of the developers or a conspiracy to make life more annoying. It'd be great to fix it, but I don't see an easy way to do so at the moment.
The Compute Express Link (CXL) microconference was held, for a second straight time, at this year's Linux Plumbers Conference. The goals for the track were to openly discuss current on-going development efforts around the core driver, as well as experimental memory management topics which lead to accommodating kernel infrastructure for new technology and use cases.
CXL session at LPC23
(i) CXL Emulation in QEMU - Progress, status and most importantly what next? The cxl qemu maintainers presented the current state of the emulation, for which significant progress has been made, extending support beyond basic enablement. During this year, features such as volatile devices, CDAT, poison and injection infrastructure have been added upstream qemu, while several others are in the process, such as CCI/mailbox, Scan Media and dynamic capacity. There was also further highlighting of the latter, for which DCD support was presented along with extent management issues found in the 3.0 spec. Similarly, Fabric Management was another important topic, continuing the debate about qemu's role in FM development, which is still quite early. Concerns about the production (beyond testing) use cases for CCI kernel support were discussed, as well as semantics and interfaces that constrain qemu, such as host and switch coupling and differences with BMC behavior.
(ii) CXL Type-2 core support. The state and purpose of existing experimental support for type 2 (accelerators) devices was presented, for both the kernel and qemu sides. The kernel support led to preliminary abstraction improvement work being upstreamed, facilitating actual accelerator integration with the cxl core driver. However, the rest is merely guess work and the floor is open for an actual hardware backed proposal. In addition, HDM-DB support would also be welcomed as a step forward. The qemu side is very basic and designed to just exercise core checks, for which it's emulation should be limited, specially in light of cxl_test.
(iii) Plumbing challenges in Dynamic capacity device. An in-depth coverage and discussion, from a kernel side, of the state of DCD support and considerations around corner cases. Semantics of releasing DC for full partial extents (ranges) are two different beasts altogether. Releasing all the already given memory can simply require memory being offline and be done, avoiding unnecessary complexity in the kernel. Therefore the kernel can perfectly well reject the request, and FM design should keep that into consideration. Partial extents, on the other hand, are unsupported for the sake of simplicity, at least until a solid industry use case comes along. Forced DC removal of online memory semantics were also discussed, emphasizing that such DC memory is not guaranteed to ever be given back by the kernel, mapped or not. Forcing the event, the hardware does not care and the kernel has most likely crashed anyway. Support for extent tagging was another topic, establishing the need for supporting it, coupling a device to a tag domain, being a sensible use case. For now at least, the implementation can be kept to to simply enumerate tags and the necessary attributes to leave the memory matching to userspace, instead of more complex surgeries to create DAX devices on specific extents, dealing with sparse regions.
(iv) Adding RAS Support for CXL Port Devices. Starting with a general overview of RAS, this touched on the current state for support in CXL 1.1 and 2.0. Special handling is required for RCH: due to the RCRB implementation, the RCH downstream port does not have a BDF, needed for AER error handling; this work was merged in v6.7. As for CXL Virtual Hierarchy implementation, it is left still open, potentially things could move away from the PCIe port service driver model, which is not entirely liked. There are however, clear requirements: not-CXL specific (AER is a PCIe protocol, used by CXL.io); implement driver callback logic specific to that technology or device, giving flexibility to handle that specific need; and allow enable/disable on a per-device granularity. There were discussions around the order for which a registration handler is added in the PCI port driver, noting that it made sense to go top-down from the port and searching children, instead of written from a lower level.
(v) Shared CXL 3 memory: what will be required? Overview of the state, semantics and requirements for supporting shared fabric attached memory (FAM). A strong enablement use case is leveraging applications that already handle data sets in files. In addition appropriate workload candidates will fit the "master writer, multiple readers" read-only model for which this sort of machinery would make sense. Early results show that the benefits can out-weigh costly remote CXL memory access such as fitting larger data sets in FAM that would otherwise be possible in a single host. Similarly this avoids cache-coherency costs by simply never modifying the memory. A number of concrete data science and AI usecases were presented. Shared FAM is meant to be mmap-able, file-backed, special purpose memory, for which a FAMFS prototype is described, overcoming limitations of just using DAX device/FSDAX, such as distributing metadata in a shareable way.
(vi) CXL Memory Tiering for heterogenous computing. Discusses the pros and cons of interleaving heterogeneous (ie: DRAM and CXL) memory through hardware and/or software for bandwidth optimization. Hardware interleaving is simple to configure through the BIOS, but limited by not allowing the OS to manage allocations, otherwise hiding the NUMA topology (single node) as well as being a static configuration. The software interleaving solves these limitations with hardware and relies on weighted nodes for allocation distribution when doing the initial mapping (vma). Several interfaces have been posted, which incrementally are converging into a NUMA node based interface. The caveat is to have a single (configurable) system-wide set of weights, or to allow more flexibility, such as hierarchically through cgroups - something which has not been particularly sold yet. Combining both hardware and software models relies on within a socket, splitting channels among respective DDR and CXL NUMA nodes for which software can explicitly (numactl) set the interleaving - it is still restrained however by being static as the BIOS is in charge of setting the number of NUMA nodes.
(vii) A move_pages() equivalent for physical memory. Through an experimental interface, this focused on the semantics of tiering and device driven page movement. There are currently various mechanisms for access detection, such as PMU-based, fault hinting for page promotion and idle bit page monitoring; each with its set of limitations, while runtime overhead is a universal concern. Hardware mechanisms could help with the burden but the problem is that devices only know physical memory and must therefore do expensive reverse mapping lookups; nor are there any interfaces for this, and it is difficult to with out hardware standardization. A good starting point would be to keep the suggested move_phys_pages as an interface, but not have it be an actual syscall.
Zubrin lies like he breathes, not bothering even calculate in Excel, not to mention take integrals!
But they continue to believe him — because it's Zubrin!
When they discussed his "engine on salt of Uranium" [NSWR — zaitcev] I wrote that the engine will not work in principle, because a reactor can only work in case of effective deceleration of neutrons, but already at the temperature of the moderator of 3000 degrees (like in KIWI), the cross-section of fission decreases 10 times, and the critical mass increases proportionally. But nobody paid attention — who am I, who is Zubrin!
The core has to be hot, and the moderator has to be cool, this is essential.
But they continued to fantasize, is it going to be 100,000 degrees in there, or only 10,000?
No matter how much I pointed out the principal contradiction — here is the cold sub-critical solution, and here is super-critical plasma, only in a meter or two away, and therefore neutrons from this plasma fly into the solution — which will inevitably capture them, decelerate, and react, and therefore the whole concept goes down the toilet.
But they disucss this salt engine over decades, without trying to check Zubrin's claims.
All "normal" nuclear reactors work only in the region between "first" (including the delayed neutrons) and "second" (with fast neutrons) criticalities. Only in this region, control of the reactor is possible. By the way, the difference in breeding ratios is only 1.000 and 1.007 for slow neutrons and 1.002 for the fast ones (in case of Plutonium, this much is the case even for slow neutrons).
And by the way, average delay for delayed neutrons is 0.1 seconds! The solution has to remain in the active zone for 100 milliseconds, in order to capture the delayed neutrons! Not even the solid phase RD-0410 reached that much.
Therefore, Zubrin's engine must be critical at the prompt neutrons. And because the moderator underperforms because it's hot, prompt neutrons become indistinguishable from fission neutrons, and therefore the density of plasma has to be the same as density of metal in order to achieve criticality — that is to say, almost 20 g/sm^3 for Uranium.
But this persuades nobody, because Zubrin is Zubrin, and who are you?
It all began as a discussion of Mars Direct among geeks, but escalated quickly.
Note: if you wish to follow Linux Security Summit announcements and event updates via Mastodon, see https://social.kernel.org/LinuxSecSummit. You can follow this via the Fediverse or the RSS reader of your choice.
The current plan is to be co-located in Vienna with OSS-EU. We don’t have exact dates to give (still finding conference space) but it will be three days on the week of 16 September.
As a reminder, The live stream of each main track of Linux Plumbers Conference will be available in real time on Youtube. The Links are now live in the timetable. To view, go to the Schedule Overview and click on the paperclip on the upper right of the track you want to watch to bring up the Live Stream URL.
Live Stream viewers may interact over chat by joining the Matrix Room of that event. To see all our Matrix rooms for Plumbers, go to the space #lpc2023:lpc.events in matrix. The room names should be pretty intuitive.
We’ll be holding a BBB Training session on Thursday (8 November) at:
7am PST, 10am EST, 3pm UTC, 4pm CET, 8:30pm IST, 12am Friday JST
This will be recorded so that you can watch it later.
What is BBB? It’s an open source video software, similar to Zoom and Google Meets, but is much better for interactions between remote attendees and a live audience.
There are several features that BBB provides, and this training session will go over the common ones that you will likely use during your presentation.
This session is highly recommend for those that are presenting remotely, and may also be useful for those that are only attending remotely, to get a feel for the platform. In person attendees are welcome too, but we’ll have shepherds in the conference rooms on the day to help you out.
Linus has pulled the initial GSP firmware support for nouveau. This is just the first set of work to use the new GSP firmware and there are likely many challenges and improvements ahead.
To get this working you need to install the firmware which hasn't landed in linux-firmware yet.
For Fedora this copr has the firmware in the necessary places:
Hopefully we can upstream that in next week or so.
If you have an ADA based GPU then it should just try and work out of the box, if you have Turing or Ampere you currently need to pass nouveau.config=NvGspRm=1 on the kernel command line to attempt to use GSP.
Going forward, I've got a few fixes and stabilization bits to land, which we will concentrate on for 6.7, then going forward we have to work out how to keep it up to date and support new hardware and how to add new features.
"Why does ACPI exist" - - the greatest thread in the history of forums, locked by a moderator after 12,239 pages of heated debate, wait no let me start again.
Why does ACPI exist? In the beforetimes power management on x86 was done by jumping to an opaque BIOS entry point and hoping it would do the right thing. It frequently didn't. We called this Advanced Power Management (Advanced because before this power management involved custom drivers for every machine and everyone agreed that this was a bad idea), and it involved the firmware having to save and restore the state of every piece of hardware in the system. This meant that assumptions about hardware configuration were baked into the firmware - failed to program your graphics card exactly the way the BIOS expected? Hurrah! It's only saved and restored a subset of the state that you configured and now potential data corruption for you. The developers of ACPI made the reasonable decision that, well, maybe since the OS was the one setting state in the first place, the OS should restore it.
So far so good. But some state is fundamentally device specific, at a level that the OS generally ignores. How should this state be managed? One way to do that would be to have the OS know about the device specific details. Unfortunately that means you can't ship the computer without having OS support for it, which means having OS support for every device (exactly what we'd got away from with APM). This, uh, was not an option the PC industry seriously considered. The alternative is that you ship something that abstracts the details of the specific hardware and makes that abstraction available to the OS. This is what ACPI does, and it's also what things like Device Tree do. Both provide static information about how the platform is configured, which can then be consumed by the OS and avoid needing device-specific drivers or configuration to be built-in.
The main distinction between Device Tree and ACPI is that Device Tree is purely a description of the hardware that exists, and so still requires the OS to know what's possible - if you add a new type of power controller, for instance, you need to add a driver for that to the OS before you can express that via Device Tree. ACPI decided to include an interpreted language to allow vendors to expose functionality to the OS without the OS needing to know about the underlying hardware. So, for instance, ACPI allows you to associate a device with a function to power down that device. That function may, when executed, trigger a bunch of register accesses to a piece of hardware otherwise not exposed to the OS, and that hardware may then cut the power rail to the device to power it down entirely. And that can be done without the OS having to know anything about the control hardware.
How is this better than just calling into the firmware to do it? Because the fact that ACPI declares that it's going to access these registers means the OS can figure out that it shouldn't, because it might otherwise collide with what the firmware is doing. With APM we had no visibility into that - if the OS tried to touch the hardware at the same time APM did, boom, almost impossible to debug failures (This is why various hardware monitoring drivers refuse to load by default on Linux - the firmware declares that it's going to touch those registers itself, so Linux decides not to in order to avoid race conditions and potential hardware damage. In many cases the firmware offers a collaborative interface to obtain the same data, and a driver can be written to get that. this bug comment discusses this for a specific board)
Unfortunately ACPI doesn't entirely remove opaque firmware from the equation - ACPI methods can still trigger System Management Mode, which is basically a fancy way to say "Your computer stops running your OS, does something else for a while, and you have no idea what". This has all the same issues that APM did, in that if the hardware isn't in exactly the state the firmware expects, bad things can happen. While historically there were a bunch of ACPI-related issues because the spec didn't define every single possible scenario and also there was no conformance suite (eg, should the interpreter be multi-threaded? Not defined by spec, but influences whether a specific implementation will work or not!), these days overall compatibility is pretty solid and the vast majority of systems work just fine - but we do still have some issues that are largely associated with System Management Mode.
One example is a recent Lenovo one, where the firmware appears to try to poke the NVME drive on resume. There's some indication that this is intended to deal with transparently unlocking self-encrypting drives on resume, but it seems to do so without taking IOMMU configuration into account and so things explode. It's kind of understandable why a vendor would implement something like this, but it's also kind of understandable that doing so without OS cooperation may end badly.
This isn't something that ACPI enabled - in the absence of ACPI firmware vendors would just be doing this unilaterally with even less OS involvement and we'd probably have even more of these issues. Ideally we'd "simply" have hardware that didn't support transitioning back to opaque code, but we don't (ARM has basically the same issue with TrustZone). In the absence of the ideal world, by and large ACPI has been a net improvement in Linux compatibility on x86 systems. It certainly didn't remove the "Everything is Windows" mentality that many vendors have, but it meant we largely only needed to ensure that Linux behaved the same way as Windows in a finite number of ways (ie, the behaviour of the ACPI interpreter) rather than in every single hardware driver, and so the chances that a new machine will work out of the box are much greater than they were in the pre-ACPI period.
There's an alternative universe where we decided to teach the kernel about every piece of hardware it should run on. Fortunately (or, well, unfortunately) we've seen that in the ARM world. Most device-specific simply never reaches mainline, and most users are stuck running ancient kernels as a result. Imagine every x86 device vendor shipping their own kernel optimised for their hardware, and now imagine how well that works out given the quality of their firmware. Does that really seem better to you?
It's understandable why ACPI has a poor reputation. But it's also hard to figure out what would work better in the real world. We could have built something similar on top of Open Firmware instead but the distinction wouldn't be terribly meaningful - we'd just have Forth instead of the ACPI bytecode language. Longing for a non-ACPI world without presenting something that's better and actually stands a reasonable chance of adoption doesn't make the world a better place.
The Pixel 8 hardware (Tensor G3) supports the ARM Memory Tagging Extension (MTE), and software support is available both in Android userspace and the Linux kernel. This feature is a powerful defense against linear buffer overflows and many types of use-after-free flaws. I’m extremely happy to see this hardware finally available in the real world.
Turning it on for userspace is already wired up the Android UI: Settings / System / Developer options / Memory Tagging Extension / Enable MTE until you turn if off. Once enabled it will internally change an Android “system property” named “arm64.memtag.bootctl” by adding the option “memtag“.
Turning it on for the kernel is slightly more involved, but not difficult at all. This requires manually setting the “arm64.memtag.bootctl” property mentioned above to include “memtag-kernel” as well:
Plug your phone into a system that can run the adb tool
If not already installed, install adb. For example on Debian/Ubuntu: sudo apt install adb
Turn on “USB Debugging” in the phone’s “Developer options” menu, and accept the debugging session confirmation that will pop up when you first run adb
Verify the current setting: adb shell getprop | grep memtag.bootctl
Check the results: adb shell getprop | grep memtag.bootctl
[arm64.memtag.bootctl]: [memtag,memtag-kernel]
Reboot your phone
To check that MTE is enabled for the kernel (which is implemented using Kernel Address Sanitizer’s Hardware Tagging mode), you can check the kernel command line after rebooting:
The runners for the miniconferences and kernel summit will be adding more details to each of their schedules over the coming weeks, as will the leads for the networking and toolchain tracks.
For those that are registered as in person, you are free to continue to submit Birds of a Feather(BOF) sessions. They will be allocated space in the BOF rooms on a first come, first serve basis. Please note that these BOFs will not be recorded.
We’re looking forward to a great 3 days of presentations and discussions. We hope you can join us either in-person or virtually!
The Free Software Foundation Europe and the Software Freedom Conservancy recently released a statement that they would no longer work with Eben Moglen, chairman of the Software Freedom Law Center. Eben was the general counsel for the Free Software Foundation for over 20 years, and was centrally involved in the development of version 3 of the GNU General Public License. He's devoted a great deal of his life to furthering free software.
But, as described in the joint statement, he's also acted abusively towards other members of the free software community. He's acted poorly towards his own staff. In a professional context, he's used graphically violent rhetoric to describe people he dislikes. He's screamed abuse at people attempting to do their job.
And, sadly, none of this comes as a surprise to me. As I wrote in 2017, after it became clear that Eben's opinions diverged sufficiently from the FSF's that he could no longer act as general counsel, he responded by threatening an FSF board member at an FSF-run event (various members of the board were willing to tolerate this, which is what led to me quitting the board). There's over a decade's evidence of Eben engaging in abusive behaviour towards members of the free software community, be they staff, colleagues, or just volunteers trying to make the world a better place.
When we build communities that tolerate abuse, we exclude anyone unwilling to tolerate being abused[1]. Nobody in the free software community should be expected to deal with being screamed at or threatened. Nobody should be afraid that they're about to have their sexuality outed by a former boss.
But of course there are some that will defend Eben based on his past contributions. There were people who were willing to defend Hans Reiser on that basis. We need to be clear that what these people are defending is not free software - it's the right for abusers to abuse. And in the long term, that's bad for free software.
[1] "Why don't people just get better at tolerating abuse?" is a terrible response to this. Why don't abusers stop abusing? There's fewer of them, and it should be easier.
Now that the MC selection process is finished, we’ve recovered enough passes to reopen general registration. If you still wish to register, please go to our Attend page.
Hopefully we recovered enough passes to keep registration open for a couple of weeks, if not longer, but please don’t wait …
TPMs contain a set of registers ("Platform Configuration Registers", or PCRs) that are used to track what a system boots. Each time a new event is measured, a cryptographic hash representing that event is passed to the TPM. The TPM appends that hash to the existing value in the PCR, hashes that, and stores the final result in the PCR. This means that while the PCR's value depends on the precise sequence and value of the hashes presented to it, the PCR value alone doesn't tell you what those individual events were. Different PCRs are used to store different event types, but there are still more events than there are PCRs so we can't avoid this problem by simply storing each event separately.
This is solved using the event log. The event log is simply a record of each event, stored in RAM. The algorithm the TPM uses to calculate the PCR values is known, so we can reproduce that by simply taking the events from the event log and replaying the series of events that were passed to the TPM. If the final calculated value is the same as the value in the PCR, we know that the event log is accurate, which means we now know the value of each individual event and can make an appropriate judgement regarding its security.
If any value in the event log is invalid, we'll calculate a different PCR value and it won't match. This isn't terribly helpful - we know that at least one entry in the event log doesn't match what was passed to the TPM, but we don't know which entry. That means we can't trust any of the events associated with that PCR. If you're trying to make a security determination based on this, that's going to be a problem.
PCR 7 is used to track information about the secure boot policy on the system. It contains measurements of whether or not secure boot is enabled, and which keys are trusted and untrusted on the system in question. This is extremely helpful if you want to verify that a system booted with secure boot enabled before allowing it to do something security or safety critical. Unfortunately, if the device gives you an event log that doesn't replay correctly for PCR 7, you now have no idea what the security state of the system is.
We ran into that this week. Examination of the event log revealed an additional event other than the expected ones - a measurement accompanied by the string "Boot Guard Measured S-CRTM". Boot Guard is an Intel feature where the CPU verifies the firmware is signed with a trusted key before executing it, and measures information about the firmware in the process. Previously I'd only encountered this as a measurement into PCR 0, which is the PCR used to track information about the firmware itself. But it turns out that at least some versions of Boot Guard also measure information about the Boot Guard policy into PCR 7. The argument for this is that this is effectively part of the secure boot policy - having a measurement of the Boot Guard state tells you whether Boot Guard was enabled, which tells you whether or not the CPU verified a signature on your firmware before running it (as I wrote before, I think Boot Guard has user-hostile default behaviour, and that enforcing this on consumer devices is a bad idea).
But there's a problem here. The event log is created by the firmware, and the Boot Guard measurements occur before the firmware is executed. So how do we get a log that represents them? That one's fairly simple - the firmware simply re-calculates the same measurements that Boot Guard did and creates a log entry after the fact[1]. All good.
Except. What if the firmware screws up the calculation and comes up with a different answer? The entry in the event log will now not match what was sent to the TPM, and replaying will fail. And without knowing what the actual value should be, there's no way to fix this, which means there's no way to verify the contents of PCR 7 and determine whether or not secure boot was enabled.
But there's still a fundamental source of truth - the measurement that was sent to the TPM in the first place. Inspired by Henri Nurmi's work on sniffing Bitlocker encryption keys, I asked a coworker if we could sniff the TPM traffic during boot. The TPM on the board in question uses SPI, a simple bus that can have multiple devices connected to it. In this case the system flash and the TPM are on the same SPI bus, which made things easier. The board had a flash header for external reprogramming of the firmware in the event of failure, and all SPI traffic was visible through that header. Attaching a logic analyser to this header made it simple to generate a record of that. The only problem was that the chip select line on the header was attached to the firmware flash chip, not the TPM. This was worked around by simply telling the analysis software that it should invert the sense of the chip select line, ignoring all traffic that was bound for the flash and paying attention to all other traffic. This worked in this case since the only other device on the bus was the TPM, but would cause problems in the event of multiple devices on the bus all communicating.
With the aid of this analyser plugin, I was able to dump all the TPM traffic and could then search for writes that included the "0182" sequence that corresponds to the command code for a measurement event. This gave me a couple of accesses to the locality 3 registers, which was a strong indication that they were coming from the CPU rather than from the firmware. One was for PCR 0, and one was for PCR 7. This corresponded to the two Boot Guard events that we expected from the event log. The hash in the PCR 0 measurement was the same as the hash in the event log, but the hash in the PCR 7 measurement differed from the hash in the event log. Replacing the event log value with the value actually sent to the TPM resulted in the event log now replaying correctly, supporting the hypothesis that the firmware was failing to correctly reconstruct the event.
What now? The simple thing to do is for us to simply hard code this fixup, but longer term we'd like to figure out how to reconstruct the event so we can calculate the expected value ourselves. Unfortunately there doesn't seem to be any public documentation on this. Sigh.
[1] What stops firmware on a system with no Boot Guard faking those measurements? TPMs have a concept of "localities", effectively different privilege levels. When Boot Guard performs its initial measurement into PCR 0, it does so at locality 3, a locality that's only available to the CPU. This causes PCR 0 to be initialised to a different initial value, affecting the final PCR value. The firmware can't access locality 3, so can't perform an equivalent measurement, so can't fake the value.
Linux Plumbers is now sold out and in-person registration is closed.
This year it happened not as fast as in 2022, but the registration is still sold out long before the event.
We are setting up a waitlist for in-person registration (virtual attendee places are still available). Please fill in this form and try to be clear about your reasons for wanting to attend. This year we’re giving waitlist priority to new attendees and people expected to contribute content.
The Containers and Checkpoint/Restore micro-conference focuses on both userspace and kernel related work. The micro-conference targets the wider container ecosystem ideally with participants from all major container runtimes as well as init system developers.
The microconference will be discussing recent advancements in container technologies with some of the usual candidates being:
CGroupV2 feature parity with CGroupV1
Emulation of various files and system calls through FUSE and/or Seccomp
Dealing with the eBPF-ification of the world
Making user namespaces more accessible
VFS idmap improvements
On the checkpoint/restore front, some of the potential topics include:
Restoring FUSE services
Handling GPUs
Dealing with restartable sequences
And quite likely a variety of other container and checkpoint/restore topics as things evolve between now and the event.
Past editions of this micro-conference have been the source of many developments in the Linux kernel, including:
Sriram invited me to the oneAPI meetup, and I felt I hadn't summed up the state of compute and community development in a while. Enjoy 45 minutes of opinions!
The Power Management and Thermal Control microconference focuses on power management and thermal control infrastructure, CPU and device power-management mechanisms, and thermal control methods.
In particular, we are interested in improving the thermal control infrastructure in the kernel to cover more use cases and utilizing energy-saving opportunities offered by modern hardware in new ways.
The goal is to facilitate cross-framework and cross-platform discussions that can help improve energy-awareness and thermal control in Linux.
The current list of topics proposed so far includes the following:
Work involves supporting Windows (there's a lot of specialised hardware design software that's only supported under Windows, so this isn't really avoidable), but also involves git, so I've been working on extending our support for hardware-backed SSH certificates to Windows and trying to glue that into git. In theory this doesn't sound like a hard problem, but in practice oh good heavens.
Git for Windows is built on top of msys2, which in turn is built on top of Cygwin. This is an astonishing artifact that allows you to build roughly unmodified POSIXish code on top of Windows, despite the terrible impedance mismatches inherent in this. One is that until 2017, Windows had no native support for Unix sockets. That's kind of a big deal for compatibility purposes, so Cygwin worked around it. It's, uh, kind of awful. If you're not a Cygwin/msys app but you want to implement a socket they can communicate with, you need to implement this undocumented protocol yourself. This isn't impossible, but ugh.
But going to all this trouble helps you avoid another problem! The Microsoft version of OpenSSH ships an SSH agent that doesn't use Unix sockets, but uses a named pipe instead. So if you want to communicate between Cygwinish OpenSSH (as is shipped with git for Windows) and the SSH agent shipped with Windows, you need something that bridges between those. The state of the art seems to be to use npiperelay with socat, but if you're already writing something that implements the Cygwin socket protocol you can just use npipe to talk to the shipped ssh-agent and then export your own socket interface.
And, amazingly, this all works? I've managed to hack together an SSH agent (using Go's SSH agent implementation) that can satisfy hardware backed queries itself, but forward things on to the Windows agent for compatibility with other tooling. Now I just need to figure out how to plumb it through to WSL. Sigh.
Confidential Computing is continuing to remain a popular topic in computing industry. From memory encryption to trusted I/O, hardware has been constantly improving and broadening. In the past years, confidential computing microconferences have brought together developers working on various features in hypervisors, firmware, Linux kernel, low level userspace up to container runtimes. We have discussed a broad range of topics, ranging from, hardware enablement to generic attestation workflows.
Just in the last year, we have seen support for Intel TDX and AMD SEV-SNP guests merged into Linux. Support for unaccepted memory has also landed in mainline. We have also had support for running as a CVM under Hyper-V partially merged into the kernel. However, there is still a long way to go before a complete Confidential Computing stack with open source software and Linux as the hypervisor becomes a reality. We invite contributions to this microconference to help make progress to that goal.
Please use the LPC CfP process to submit your proposals. Submissions can be made via the LPC abstract submission page. Make sure to select “Confidential Computing MC” as the track.
The IoT Microconference is a forum for developers to discuss all things IoT. Topics include tools, telemetry, device drivers, and protocols in not only the Linux kernel but also Real-Time Operating Systems such as Zephyr.
Since last year, there have been a number of new technical topics with significant updates.
Opportunities in IoT and Edge computing with the Linux /dev/accel API
Using the Thrift RPC framework between Linux and Zephyr
Zephyr’s new HTTP Server (a GSoC project)
Rust in the Zephyr RTOS: Benefits, Challenges and Missing Pieces
We are pleased to announce that the IoT Microconference is now accepting proposals!
If you are interested in presenting an IoT-related topic involving the Linux kernel, userspace tools, firmware, Zephyr, or frameworks, please upload your submission before September 15th.
On behalf of the PCI sub-system maintainers, we would like to invite everyone to join the VFIO/IOMMU/PCI micro-conference (MC) this year.
We are hoping to bring together, both in person and online, everyone interested in the VFIO, IOMMU, and PCI space to talk about the latest developments and challenges in these areas.
The PCI interconnect specification, the devices that implement it, and the system IOMMUs that provide memory and access control to them are nowadays a de-facto standard for connecting high-speed components, incorporating more and more features such as:
Address Translation Service (ATS)/Page Request Interface (PRI)
These features are aimed at high-performance systems, server and desktop computing, embedded and SoC platforms, virtualisation, and ubiquitous IoT devices.
The kernel code that enables these new system features focuses on coordination between the PCI devices, the IOMMUs they are connected to, and the VFIO layer used to manage them (for userspace access and device passthrough) with related kernel interfaces and userspace APIs to be designed in-sync and in a clean way for all three sub-systems.
The VFIO/IOMMU/PCI MC focuses on the kernel code that enables these new system features, often requiring coordination between the VFIO, IOMMU and PCI sub-systems.
Following the success of LPC 2017, 2019, 2020, 2021, and 2022 VFIO/IOMMU/PCI MC, the Linux Plumbers Conference 2023 VFIO/IOMMU/PCI track will focus on promoting discussions on the PCI core but also current kernel patches aimed at VFIO/IOMMU/PCI sub-systems with specific sessions targeting discussions requiring the three sub-systems coordination.
Older recordings can be accessed through our official YouTube channel at @linux-pci and the archived LPC 2017 VFIO/IOMMU/PCI MC web page at Linux Plumbers Conference 2017, where the audio recordings from the MC track and links to presentation materials are available.
The tentative schedule will provide an update on the current state of VFIO/IOMMU/PCI kernel sub-systems, followed by a discussion of current issues in the proposed topics.
The following was a result of last year’s successful Linux Plumbers MC:
Support for the /dev/iommufd device has been merged into the mainline kernel
The Linux kernel has grown in complexity over the years. Complete understanding of how it works via code inspection has become virtually impossible. Today, tracing is used to follow the kernel as it performs its complex tasks. Tracing is used today for much more than simply debugging. Its framework has become the way for other parts of the Linux kernel to enhance and even make possible new features. Live kernel patching is based on the infrastructure of function tracing, as well as BPF function hooks. It is now even possible to model the behavior and correctness of the system via runtime verification which attaches to trace points. There is still much more that is happening in this space, and this microconference will be the forum to explore current and new ideas.
The discussion around trace events to handle user faults initiated the event probe work around to the problem. That was to add probes on existing trace events to change their types. This works on synthetic events that can pass the user space file name of the entry of a system call to the exit of the system call which would have faulted in the file and make it available to the trace event.
Dynamically creating the events directory with the eventfs patch set is queued to be accepted. This will save memory as the dentries and inodes will only be allocated when accessed.
There’s still ongoing effort in unifying the return path tracers of function graph and kretprobes and fprobes.
Possible ideas for topics for this year’s conference:
Use of sframes. How to get user space stack traces without requiring frame pointers.
Updating perf and ftrace to extract user space stack frames from a schedulable context (as requested by NMI).
Extending user events. Now that they are in the kernel, how to make them more accessible to users and applications.
Getting more use cases with the runtime verifier. Now that the runtime verifier is in the kernel (uses tracepoints to model against), what else can it be used for.
Wider use of ftrace_regs in fprobes and rethook from fprobes because rethook may not fill all registers in pt_regs too. How BPF handles this will also be discussed.
Removing kretprobes from kprobes so that kprobe can focus on handling software breakpoint.
Object tracing (following a variable throughout each function call). This has had several patches out, but has stopped due to hard issues to overcome. A live discussion could possibly come up with a proper solution.
Hardware breakpoints and tracing memory changes. Object tracing follows a variable when it changes between function calls. But if the hardware supports it, tracing a variable when it actually changes would be more useful albeit more complex. Discussion around this may come up with a easier answer.
MMIO tracer being used in SMP. Currently the MMIO tracer does not handle race conditions. Instead, it offlines all but one CPU when it is enabled. It would be great if this could be used in normal SMP environments. There’s nothing technically preventing that from happening. It only needs some clever thinking to come up with a design to do so.
Getting perf counters onto the ftrace ring buffer. Ftrace is designed for fast tracing, and perf is a great profiler. Over the years it has been asked to have perf counters along side ftrace trace events. Perhaps its time to finally accomplish that. It could be that each function can show the perf cache misses of that function.
For more information, feel free to contact the MC Leads:
The Linux Plumbers 2023 Kernel Testing & Dependability track focuses on advancing the current state of testing of the Linux Kernel and its related infrastructure. The main purpose is to improve software quality and dependability for applications that require predictability and trust.
The goal of this micro-conference is making connections between folks working on similar projects, and help individual projects make progress.
This track is intended to promote collaboration between all the communities and people interested in the Kernel testing & dependability. This will help move the conversation forward from where we left off at the LPC 2022 Kernel Testing & Dependability MC.
We ask that any topic discussions focus on issues/problems they are facing and possible alternatives to resolving them. The Micro-conference is open to all topics related to testing on Linux, not necessarily in the kernel space.
Suggested topics:
KernelCI: Topics on improvements and enhancements for test coverage
KCIDB is continuing to gather results from many test systems: KernelCI, Red Hat’s CKI, syzbot, ARM, Gentoo, Linaro’s TuxSuite etc. The current focus is on generating common email reports based on this data and dealing with known issues.
KFENCE is continuing to aid in detecting Out-of-bound OOB accesses, use-after-free errors (UAF), Double free and Invalid free and so on.
Clang: CFI, weeding out issues upstream, etc.
Kselftest continues to add coverage for new and existing features and subsystems.
KUnit is continuing to act as the standard for some drivers and a de facto unit testing framework in the kernel
The Runtime Verification (RV) interface from Daniel Bristot de Oliveira was merged.
After a three-year hiatus, the Live Patching Microconference is back for 2023.
Accomplishments post 2019 Microconference:
API enhancements: Livepatch pre/post (un)patch callback system state change tracking was added in v5.5. The new API enhances the safety of cumulative livepatch upgrades [v5.5]
KLP-relocations: To facilitate module_disable_ro() removal, arch-specific livepatch .klp.arg sections were deprecated. Special arch section KLP-relocations (like x86 jump labels) are still supported for vmlinux cases, and are now applied at the same time as normal relocations. [v5.8]
KLP-relocations: To support target module reloading, clear KLP-relocations in livepatch modules when their target module is unloaded. This satisfies a module loader sanity check when resolving relocations on the next target module load (x86_64 only) [v6.3]
Discussion Topics
The following topics have been proposed:
Shadow variables are considered a livepatching power-feature that can require careful management, especially across livepatch up and downgrades. Is garbage collection or a refactoring of callbacks a better approach to manage these resources?
klp-relocations were originally introduced to resolve livepatch / kernel and module symbol scoping issues. Recent security features like CET and IBT suggest another use case and renewed interest in having an in-tree klp-relocation build support. Is a simple conversion utility sufficient, or does said tool require greater features?
The livepatching kselftests consist of test scripts under tools/testing/selftests and associated livepatch module code in lib/. Consolidating these under the former offers better flexibility in templating the livepatch modules as well as the benefits of building them out-of-tree. Are there any outstanding blockers to implement these changes?
arm64 support is moving forward on several fronts: toolchain, reliable stack unwinding, user space, etc. The Toolchains MC plans to address topics like CFG in ELF and handling of noinstr functions. What issues remain in livepatching and the kernel at large to fully support arm64?
Rust looks to be a hot topic at this year’s LPC. Its impact on kernel livepatching is relatively open ended as Rust code has only recently been merged in small parts. That said, which features, problems, patchsets should we be paying attention to as we all learn more about this newly supported kernel language?
These potential discussion topics were selected from on-going livepatching mailing list threads, but additional livepatching related topics are welcome for consideration as well. For ideas on what makes for an ideal Microconference topic, checkout this post.
I dug out a computer running Fedora 28, which was released 2018-04-01 - over 5 years ago. Backing up the data and re-installing seemed tedious, but the current version of Fedora is 38, and while Fedora supports updates from N to N+2 that was still going to be 5 separate upgrades. That seemed tedious, so I figured I'd just try to do an update from 28 directly to 38. This is, obviously, extremely unsupported, but what could possibly go wrong?
Running sudo dnf system-upgrade download --releasever=38 didn't successfully resolve dependencies, but sudo dnf system-upgrade download --releasever=38 --allowerasing passed and dnf started downloading 6GB of packages. And then promptly failed, since I didn't have any of the relevant signing keys. So I downloaded the fedora-gpg-keys package from F38 by hand and tried to install it, and got a signature hdr data: BAD, no. of bytes(88084) out of range error. It turns out that rpm doesn't handle cases where the signature header is larger than a few K, and RPMs from modern versions of Fedora. The obvious fix would be to install a newer version of rpm, but that wouldn't be easy without upgrading the rest of the system as well - or, alternatively, downloading a bunch of build depends and building it. Given that I'm already doing all of this in the worst way possible, let's do something different.
The relevant code in the hdrblobRead function of rpm's lib/header.c is: int32_t il_max = HEADER_TAGS_MAX; int32_t dl_max = HEADER_DATA_MAX;
which indicates that if the header in question is RPMTAG_HEADERSIGNATURES, it sets more restrictive limits on the size (no, I don't know why). So I installed rpm-libs-debuginfo, ran gdb against librpm.so.8, loaded the symbol file, and then did disassemble hdrblobRead. The relevant chunk ends up being: 0x000000000001bc81 <+81>: cmp $0x3e,%ebx 0x000000000001bc84 <+84>: mov $0xfffffff,%ecx 0x000000000001bc89 <+89>: mov $0x2000,%eax 0x000000000001bc8e <+94>: mov %r12,%rdi 0x000000000001bc91 <+97>: cmovne %ecx,%eax
which is basically "If ebx is not 0x3e, set eax to 0xffffffff - otherwise, set it to 0x2000". RPMTAG_HEADERSIGNATURES is 62, which is 0x3e, so I just opened librpm.so.8 in hexedit, went to byte 0x1bc81, and replaced 0x3e with 0xfe (an arbitrary invalid value). This has the effect of skipping the if (regionTag == RPMTAG_HEADERSIGNATURES) code and so using the default limits even if the header section in question is the signatures. And with that one byte modification, rpm from F28 would suddenly install the fedora-gpg-keys package from F38. Success!
But short-lived. dnf now believed packages had valid signatures, but sadly there were still issues. A bunch of packages in F38 had files that conflicted with packages in F28. These were largely Python 3 packages that conflicted with Python 2 packages from F28 - jumping this many releases meant that a bunch of explicit replaces and the like no longer existed. The easiest way to solve this was simply to uninstall python 2 before upgrading, and avoiding the entire transition. Another issue was that some data files had moved from libxcrypt-common to libxcrypt, and removing libxcrypt-common would remove libxcrypt and a bunch of important things that depended on it (like, for instance, systemd). So I built a fake empty package that provided libxcrypt-common and removed the actual package. Surely everything would work now?
Ha no. The final obstacle was that several packages depended on rpmlib(CaretInVersions), and building another fake package that provided that didn't work. I shouted into the void and Bill Nottingham answered - rpmlib dependencies are synthesised by rpm itself, indicating that it has the ability to handle extensions that specific packages are making use of. This made things harder, since the list is hard-coded in the binary. But since I'm already committing crimes against humanity with a hex editor, why not go further? Back to editing librpm.so.8 and finding the list of rpmlib() dependencies it provides. There were a bunch, but I couldn't really extend the list. What I could do is overwrite existing entries. I tried this a few times but (unsurprisingly) broke other things since packages depended on the feature I'd overwritten. Finally, I rewrote rpmlib(ExplicitPackageProvide) to rpmlib(CaretInVersions) (adding an extra '\0' at the end of it to deal with it being shorter than the original string) and apparently nothing I wanted to install depended on rpmlib(ExplicitPackageProvide) because dnf finished its transaction checks and prompted me to reboot to perform the update. So, I did.
And about an hour later, it rebooted and gave me a whole bunch of errors due to the fact that dbus never got started. A bit of digging revealed that I had no /etc/systemd/system/dbus.service, a symlink that was presumably introduced at some point between F28 and F38 but which didn't get automatically added in my case because well who knows. That was literally the only thing I needed to fix up after the upgrade, and on the next reboot I was presented with a gdm prompt and had a fully functional F38 machine.
You should not do this. I should not do this. This was a terrible idea. Any situation where you're binary patching your package manager to get it to let you do something is obviously a bad situation. And with hindsight performing 5 independent upgrades might have been faster. But that would have just involved me typing the same thing 5 times, while this way I learned something. And what I learned is "Terrible ideas sometimes work and so you should definitely act upon them rather than doing the sensible thing", so like I said, you should not do this in case you learn the same lesson.
In the Linux ecosystems, there are many ways to build all the software used to put together a running system. Whether it’s building all the binary packages for a binary Linux distribution, using a source-based distribution, or building an embedded system from scratch, there are a lot of shared challenges which each system solves in its own way.
This microconference is a way to get people who work on disparate build systems to discuss common problems and possible shared solutions across the entire problem space. The kinds of topics we want to discuss are the following:
Bootstrapping the build system
Cross building software
Make, autoconf, and other similar software build tools
Managing software with language-specific package managers
Patch sharing
Building within a container
Build systems for building containers
License gathering and verification
Security updates
SBOMS
Software chain-of-trust
Repeatable builds
Documentation and education
Finding the next generation of maintainers
Build-system visibility within the wider Plumbers attendeesThis is not a definitive list, and you are free to post abstracts for other related topics.
Build Systems micorconference would like to gather representatives (developers and maintainers) from all the various build systems and related technologies. This is not a definitive list of possible attendees.
Android
Arch Linux
Buildroot
ChromeOS
Gentoo
OpenEmbedded
OpenWRT/LEDE
Yocto Project
Other traditional Binary Packaged distributions
For more information, feel free to contact the MC Leads:
The initial NVK (nouveau vulkan) experimental driver has been merged into mesa master[1], and although there's lots of work to be done before it's application ready, the main reason it was merged was because the initial kernel work needed was merged into drm-misc-next[2] and will then go to drm-next for the 6.6 merge window. (This work is separate from the GSP firmware enablement required for reclocking, that is a parallel development, needed to make nvk useable). Faith at Collabora will have a blog post about the Mesa side, this is more about the kernel journey.
What was needed in the kernel?
The nouveau kernel API was written 10 years or more ago, and was designed around OpenGL at the time. There were two major restrictions in the current uAPI that made it unsuitable for Vulkan.
buffer objects (physical memory allocations) were allocated 1:1 with virtual memory allocations for a file descriptor. This meant the kernel managed the virtual address space. For proper Vulkan support, the bo allocation and vm allocation have to be separate, and userspace should control the virtual address space.
Command submission didn't use sync objects. The nouveau command submission wasn't wired up to the modern sync objects. These are pretty much a requirement for Vulkan fencing and semaphores to work properly.
How to implement these?
When we kicked off the nvk idea I made a first pass at implementing a new user API, to allow the above features. I took at look at how the GPU VMA management was done in current drivers and realized that there was a scope for a common component to manage the GPU VA space. I did a hacky implementation of some common code and a nouveau implementation. Luckily at the time, Danilo Krummrich had joined my team at Red Hat and needed more kernel development experience in GPU drivers. I handed my sketchy implementation to Danilo and let him run with it. He spent a lot of time learning and writing copious code. His GPU VA manager code was merged into drm-misc-next last week and his nouveau code landed today.
What is the GPU VA manager?
The idea behind the GPU VA manager is that there is no need for every driver to implement something that should essentially not be a hardware specific problem. The manager is designed to track VA allocations from userspace, and keep track of what GEM objects they are currently bound to. The implementation went through a few twists and turns and experiments.
For a long period we considered using maple tree as the core of it, but we hit a number of messy interactions between the dma-fence locking and memory allocations required to add new nodes to the maple tree. The dma-fence critical section is a hard requirement to make others deal with. In the end Danilo used an rbtree to track things. We will revisit if we can deal with maple tree again in the future.
We had a long discussion and a couple of implement it both ways and see, on whether we needed to track empty sparse VMA ranges in the manager or not, nouveau wanted these but generically we weren't sure they were helpful, but that also affected the uAPI as it needed explicit operations to create/drop these. In the end we started tracking these in the driver and left the core VA manager cleaner.
Now the code is in tree we will start to push future drivers to use it instead of spinning their own.
What changes are needed for nouveau?
Now that the VAs are being tracked, the nouveau API needed two new entrypoints. Since BO allocation will no longer create a VM, a new API is needed to bind BO allocations with VM addresses. This is called the VM_BIND API. It has two variants
a synchronous version that immediately maps a BO to a VM and is used for the common allocation paths.
an asynchronous version that is modeled after the Vulkan sparse API, and takes in/out sync objects, which use the drm scheduler to schedule the vm/bo binding.
The VM BIND backend then does all the page table manipulation required.
The second API added was an EXEC call. This takes in/out sync objects and a set of addresses that point to command buffers to execute. This uses the drm scheduler to deal with the synchronization and hands the firmware the command buffer address to execute.
Internally for nouveau this meant having to add support for the drm scheduler, adding new internal page table manipulation APIs, and wiring up the GPU VA.
Shoutouts:
My input was the sketchy sketch at the start, and doing the userspace changes to the nvk codebase to allow testing.
The biggest shoutout to Danilo, who took a sketchy sketch of what things should look like, created a real implementation, did all the experimental ideas I threw at him, and threw them and others back at me, negotiated with other drivers to use the common code, and built a great foundational piece of drm kernel infrastructure.
Faith at Collabora who has done the bulk of the work on nvk did a code review at the end and pointed out some missing pieces of the API and the optimisations it enables.
Karol at Red Hat on the main nvk driver and Ben at Red Hat for nouveau advice on how things worked, while he smashed away at the GSP rock.
(and anyone else who has contributed to nvk, nouveau and even NVIDIA for some bits :-)


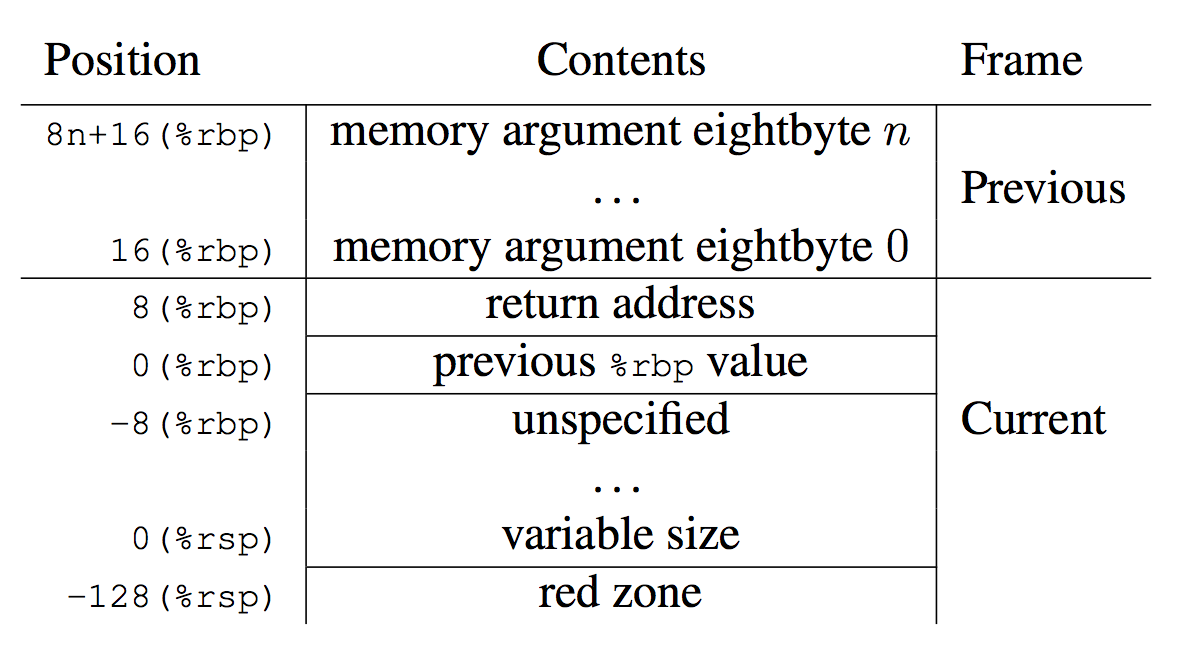
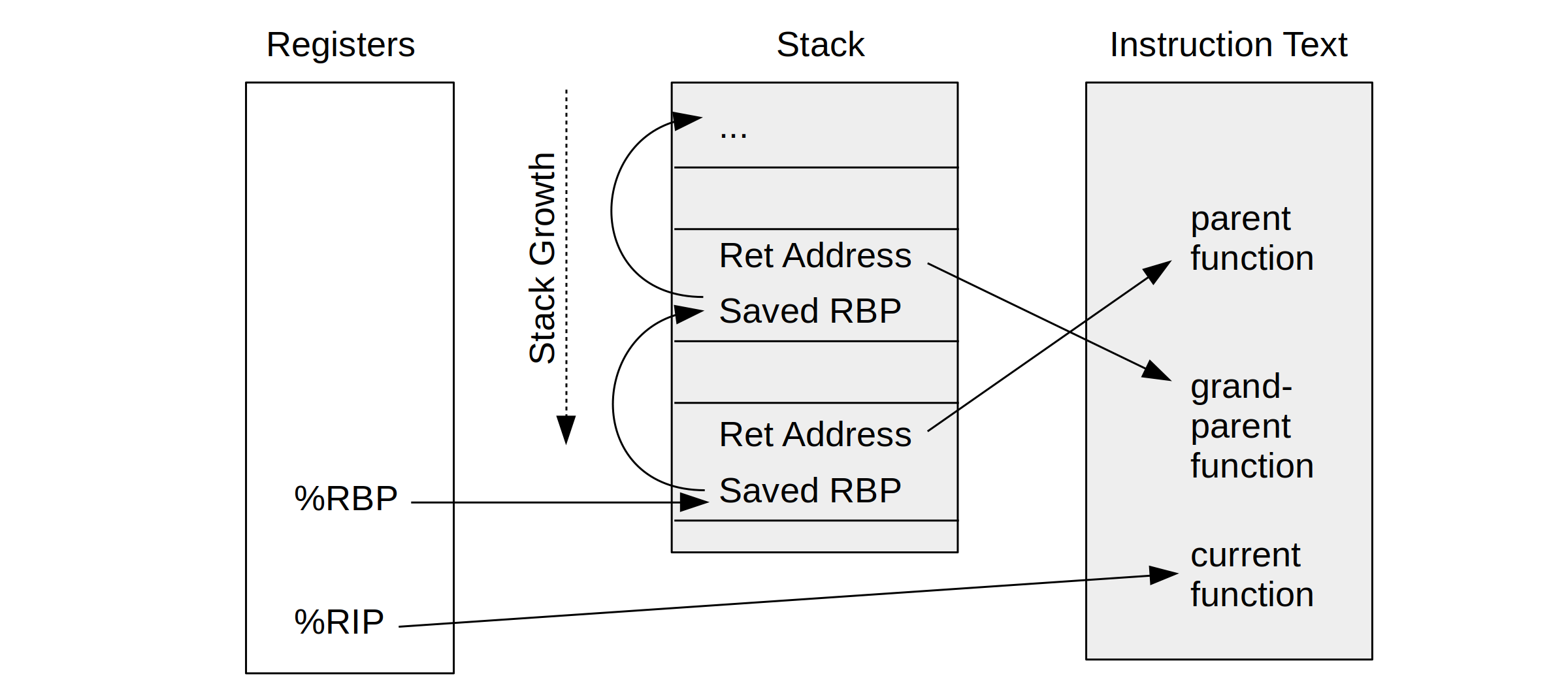
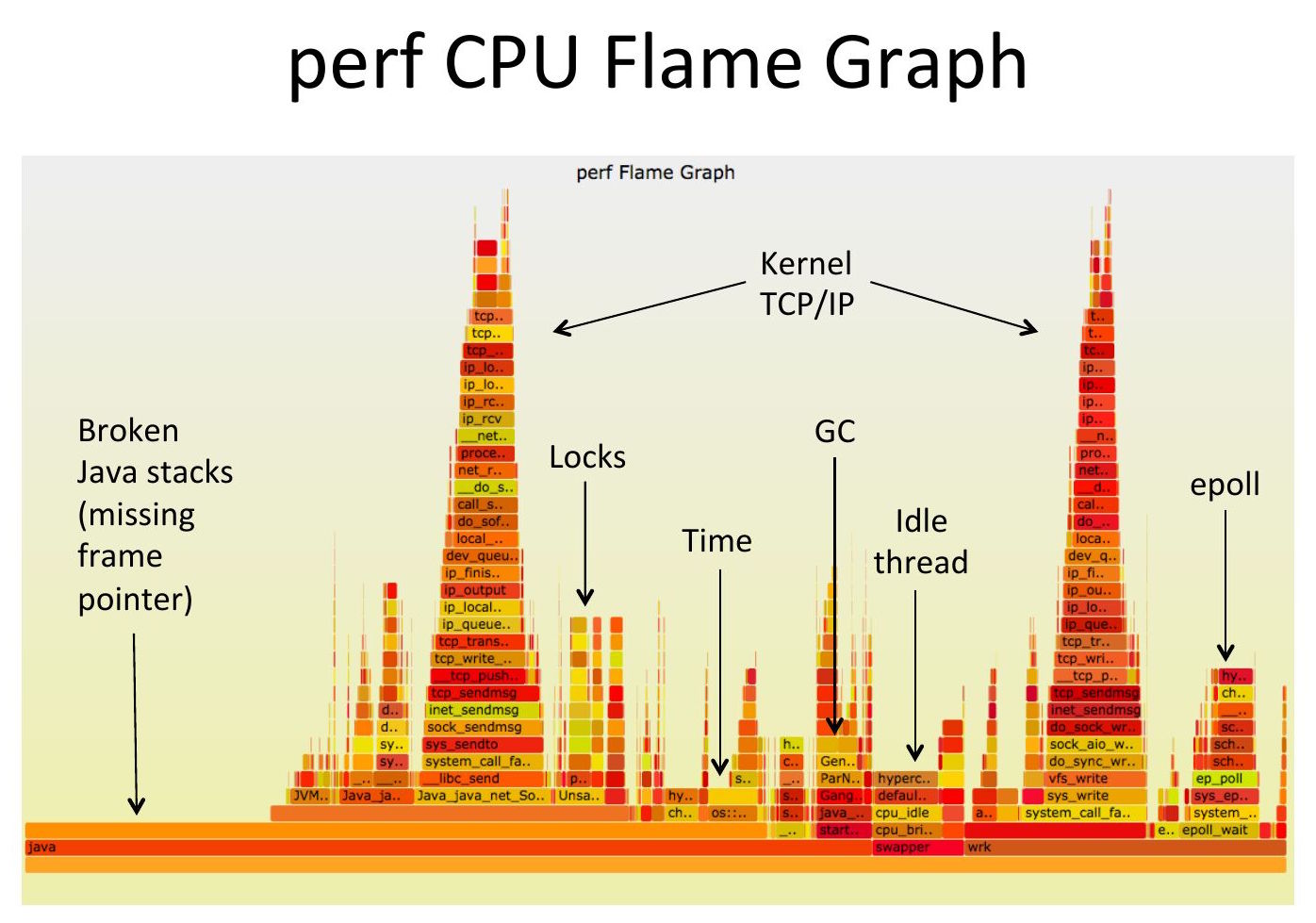



{kind=link}